
11 Essential Plots That Data Scientists Use 95% of the Time
Most important plots in data science.

Visualizations are critical in understanding complex data patterns and relationships.

They offer a concise way to understand the:
intricacies of statistical models
validate model assumptions
evaluate model performance, and much more.
Thus, it is important to be aware of the most important and helpful plots in data science.
The visual below depicts the 11 most important and must-know plots in data science:
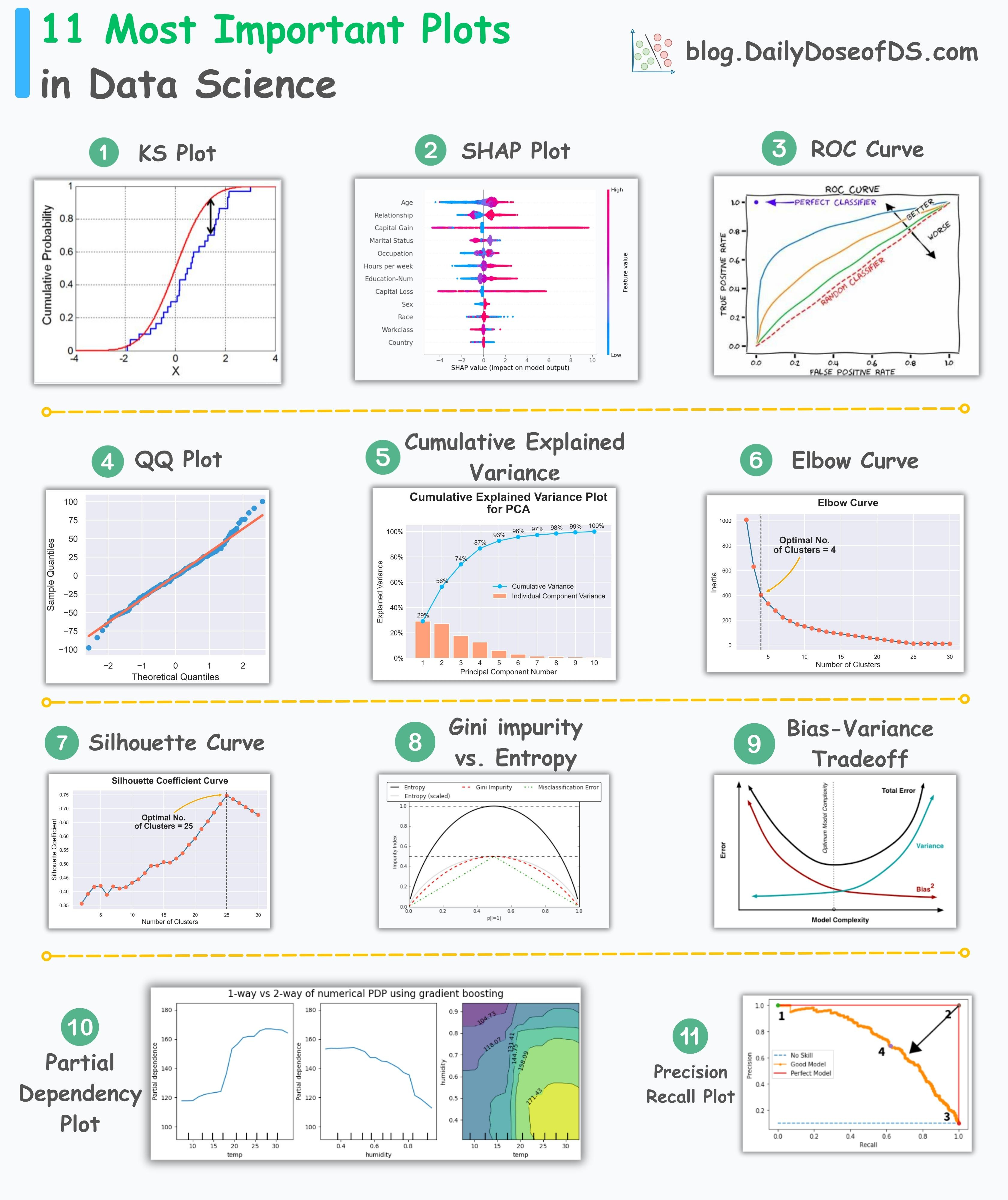
Today, let’s understand them briefly and how they are used.
KS Plot:

It is used to assess the distributional differences.
The core idea is to measure the maximum distance between the cumulative distribution functions (CDF) of two distributions.
The lower the maximum distance, the more likely they belong to the same distribution.
Thus, instead of a “plot”, it is mainly interpreted as a “statistical test” to determine distributional differences.
SHAP Plot:

It summarizes feature importance to a model’s predictions by considering interactions/dependencies between them.
It is useful in determining how different values (low or high) of a feature affect the overall output.
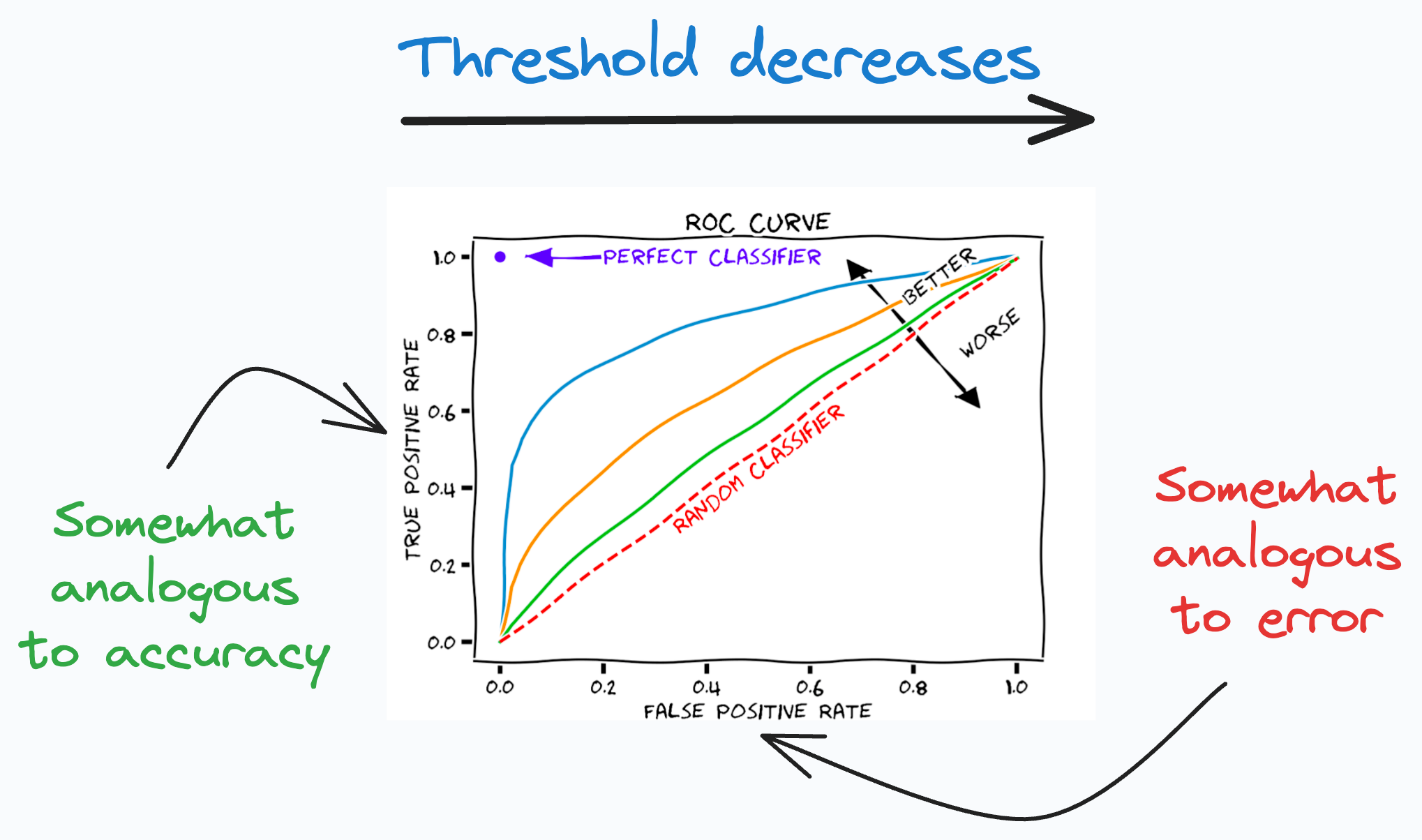
ROC Curve:

It depicts the tradeoff between the true positive rate (good performance) and the false positive rate (bad performance) across different classification thresholds.
The idea is to balance TPR (good performance) vs. FPR (bad performance).
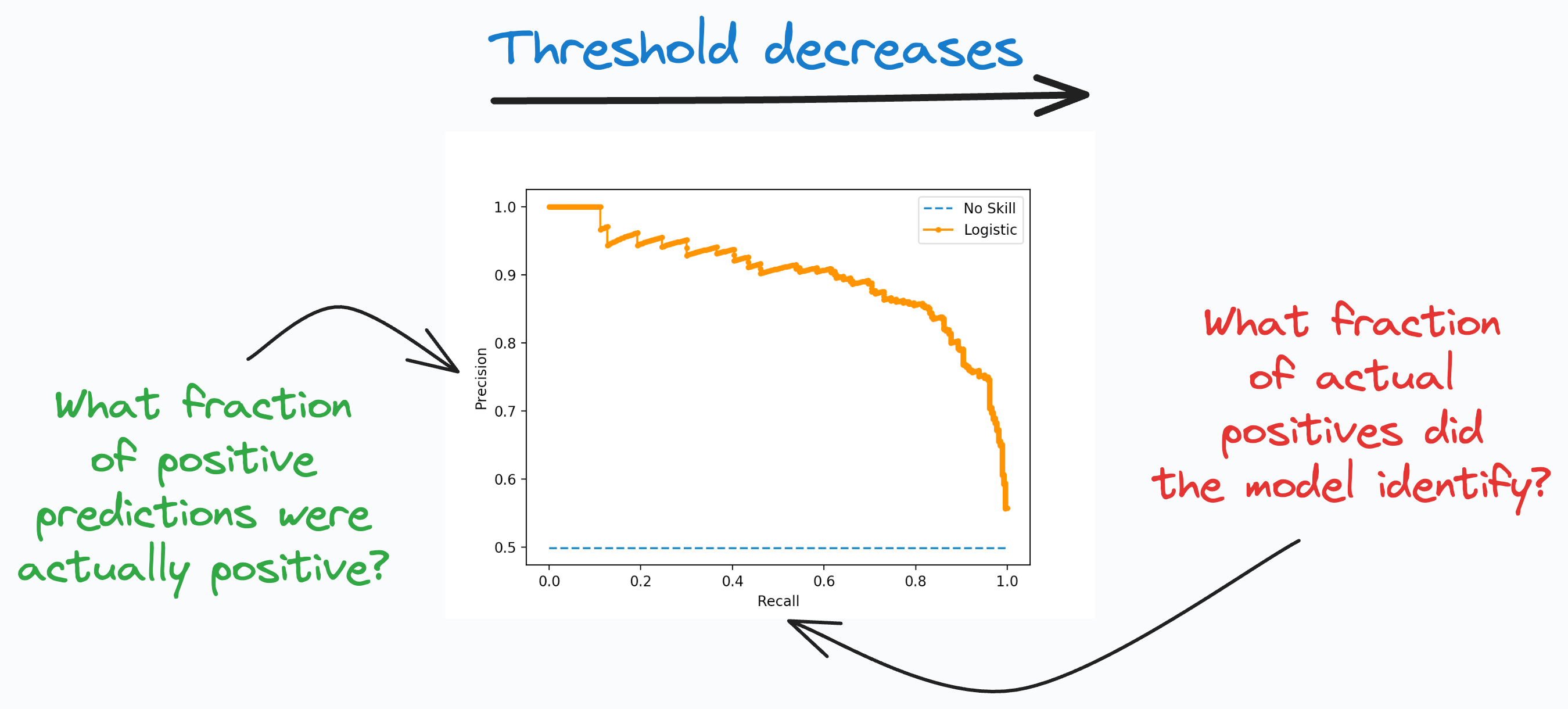
Precision-Recall Curve:

It depicts the tradeoff between Precision and Recall across different classification thresholds.
QQ Plot:

It assesses the distributional similarity between observed data and theoretical distribution.
It plots the quantiles of the two distributions against each other.
Deviations from the straight line indicate a departure from the assumed distribution.
Cumulative Explained Variance Plot:

It is useful in determining the number of dimensions we can reduce our data to while preserving max variance during PCA.
Read the full article on PCA here for more clarity: Formulating the Principal Component Analysis (PCA) Algorithm From Scratch.
Elbow Curve:

The plot helps identify the optimal number of clusters for the k-means algorithm.
The point of the elbow depicts the ideal number of clusters.
Silhouette Curve:

The Elbow curve is often ineffective when you have plenty of clusters.
Silhouette Curve is a better alternative, as depicted above.
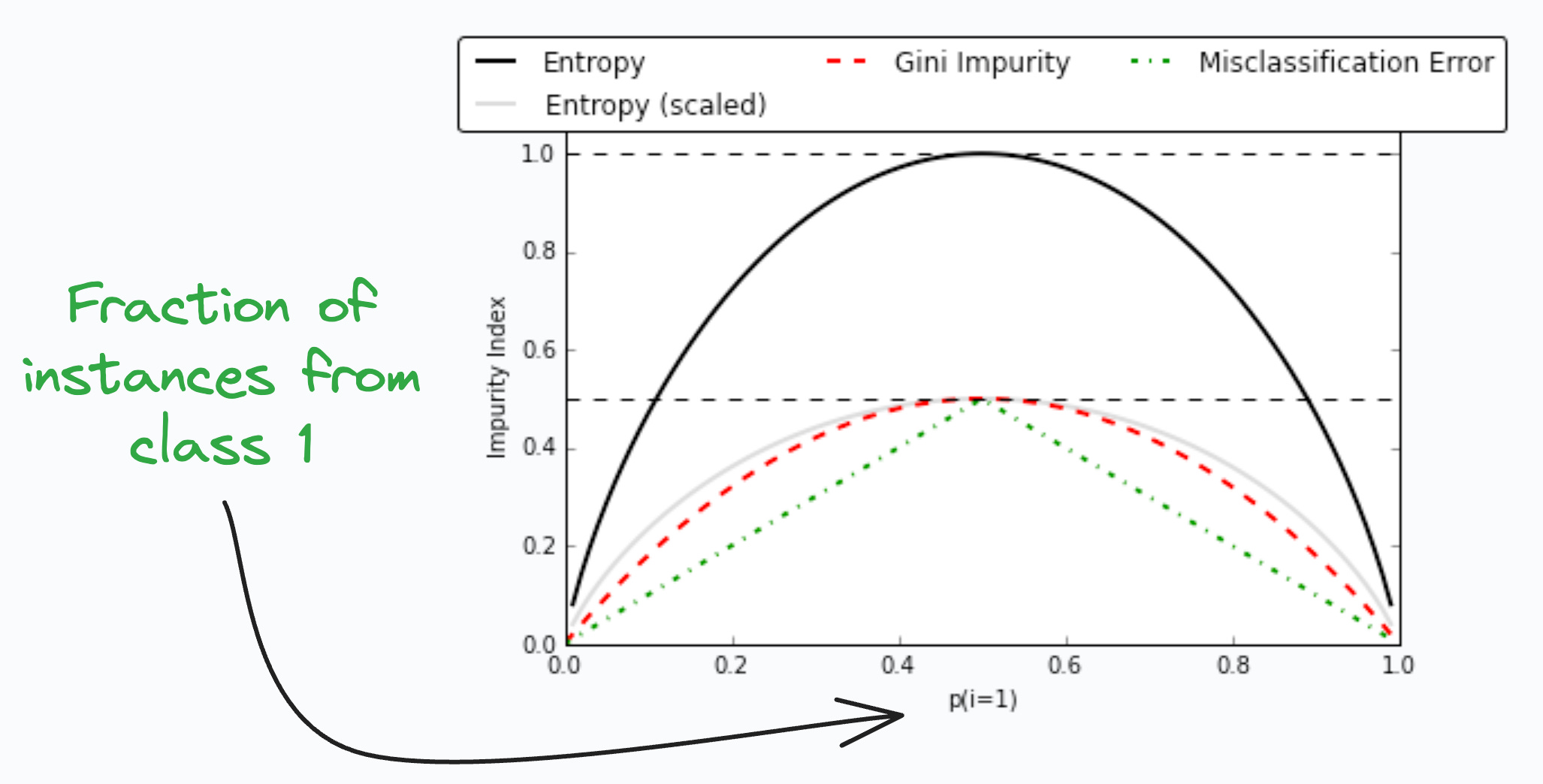
Gini-Impurity and Entropy:

They are used to measure the impurity or disorder of a node or split in a decision tree.
The plot compares Gini impurity and Entropy across different splits.
This provides insights into the tradeoff between these measures.
Bias-Variance Tradeoff:

It’s probably the most popular plot on this list.
It is used to find the right balance between the bias and the variance of a model against complexity.
Partial Dependency Plots:
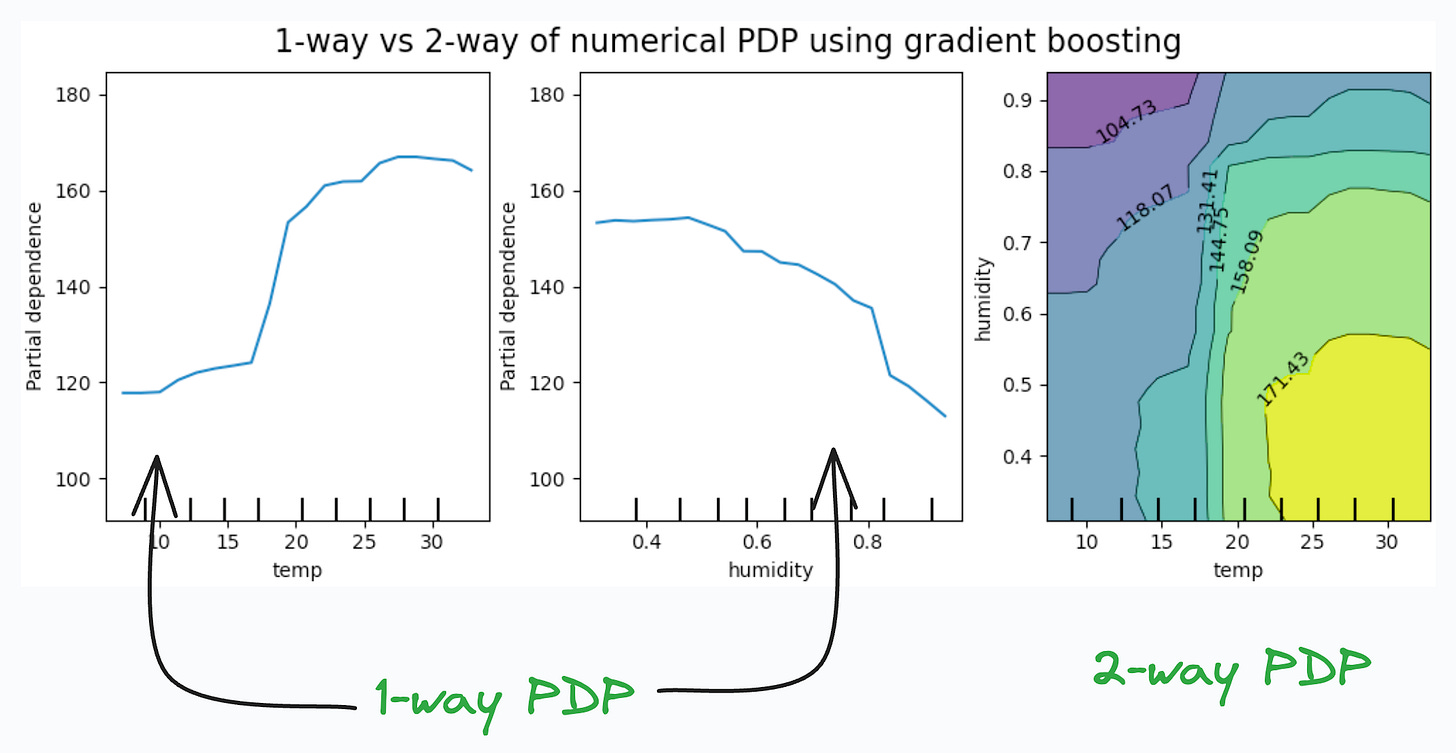
Depicts the dependence between target and features.
A plot between the target and one feature forms → 1-way PDP.
A plot between the target and two feature forms → 2-way PDP.
In the leftmost plot, an increase in temperature generally results in a higher target value.







👉 Over to you: Which important plots have I missed here?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Model Compression: A Critical Step Towards Efficient Machine Learning.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
Formulating and Implementing the t-SNE Algorithm From Scratch.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Next, top k best plots and visualizations for reporting please!
Do you have the python code for your plots? If so, could you share it?