
A Practical and Intuitive Guide to Building Multi-task Learning Models
Building MTL models in PyTorch.

Yesterday’s post discussed four critical model training paradigms used in training many real-world ML models.
Here’s the visual from that post for a quick recap:
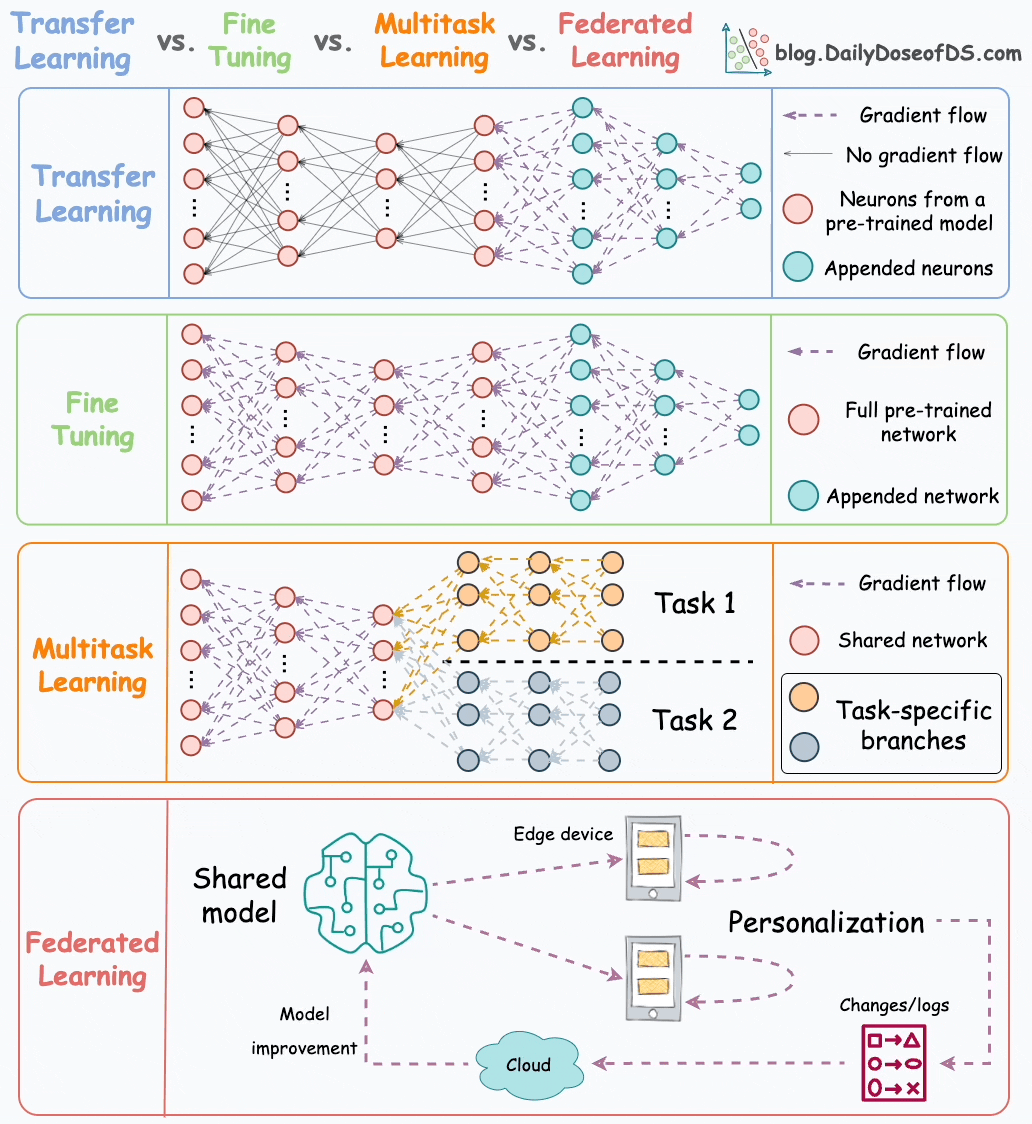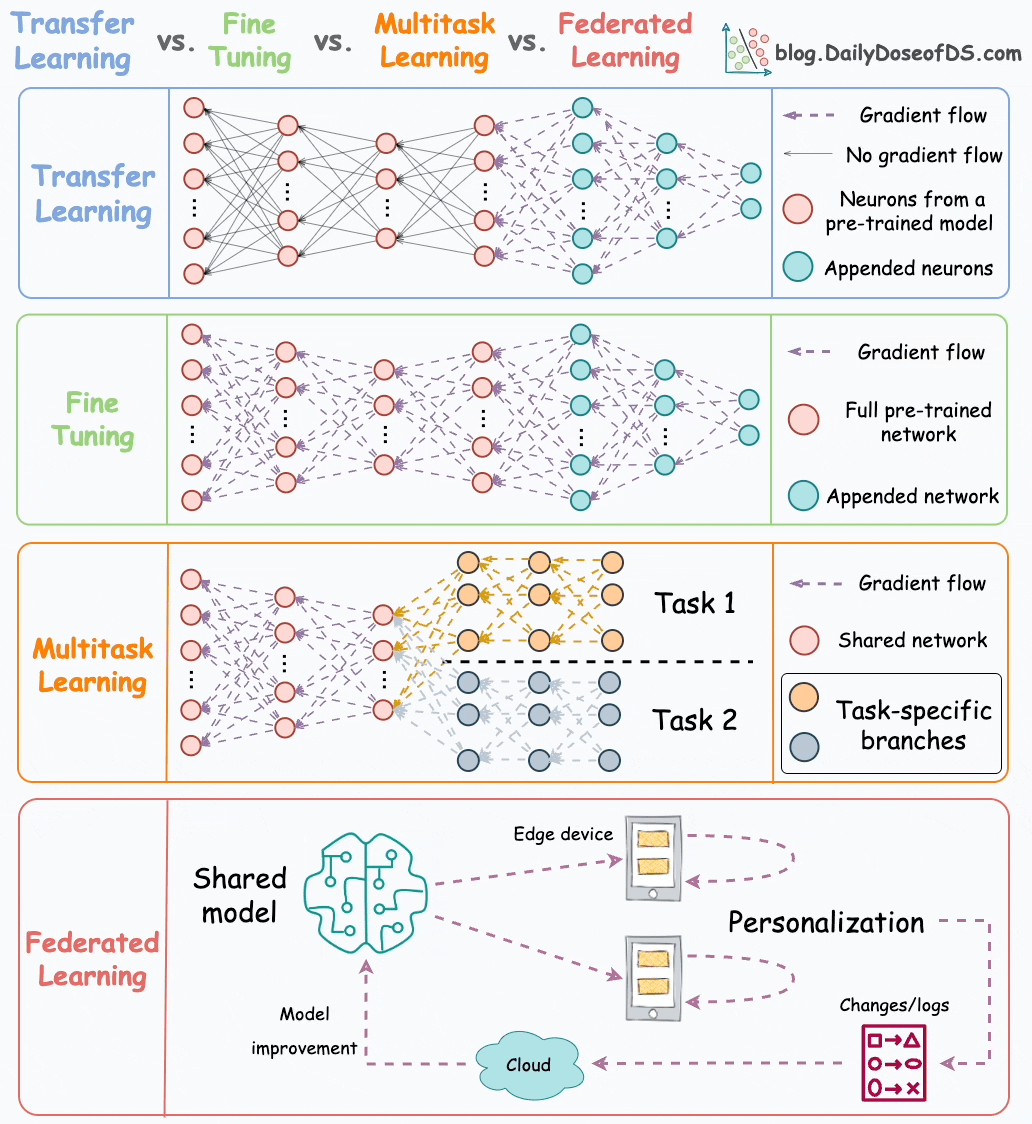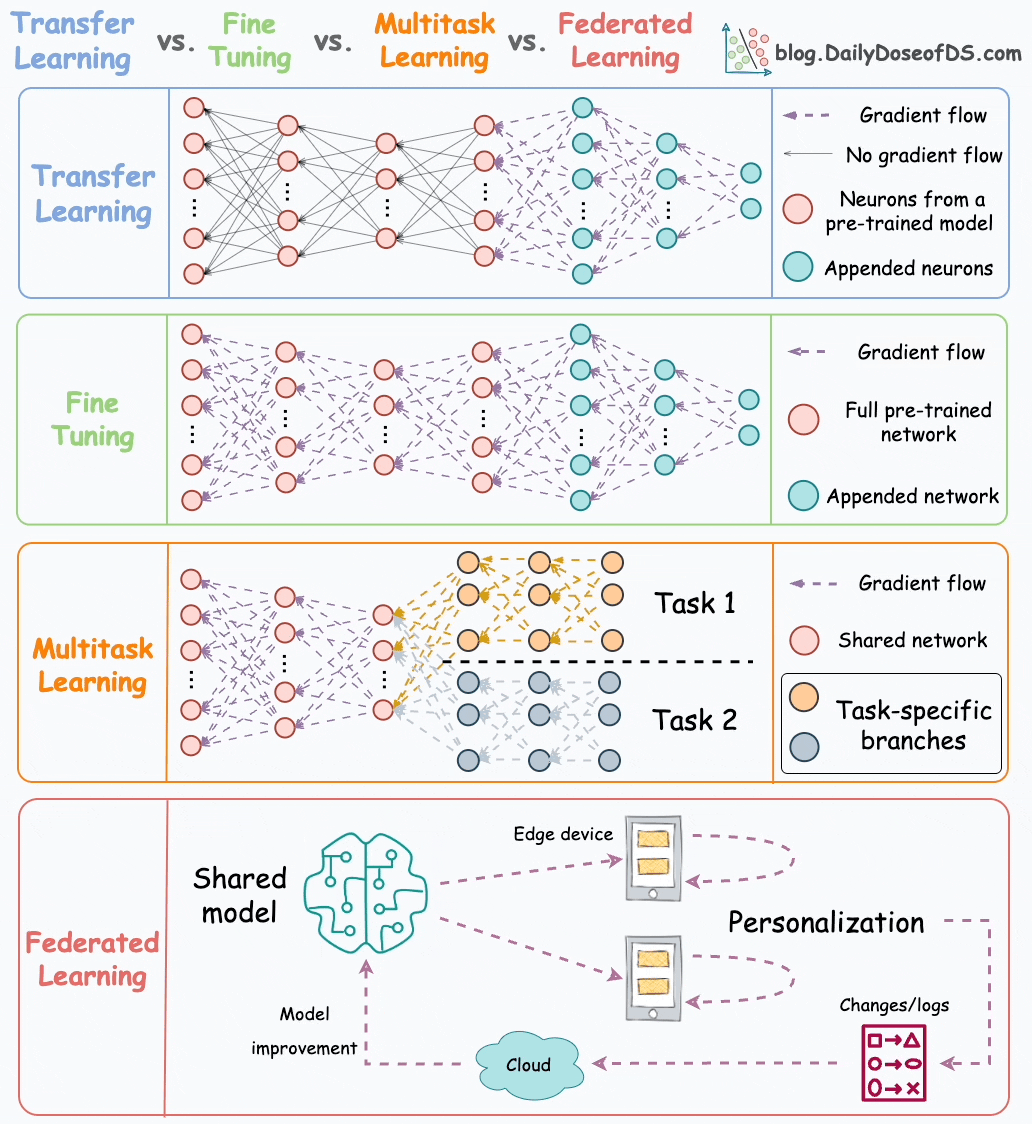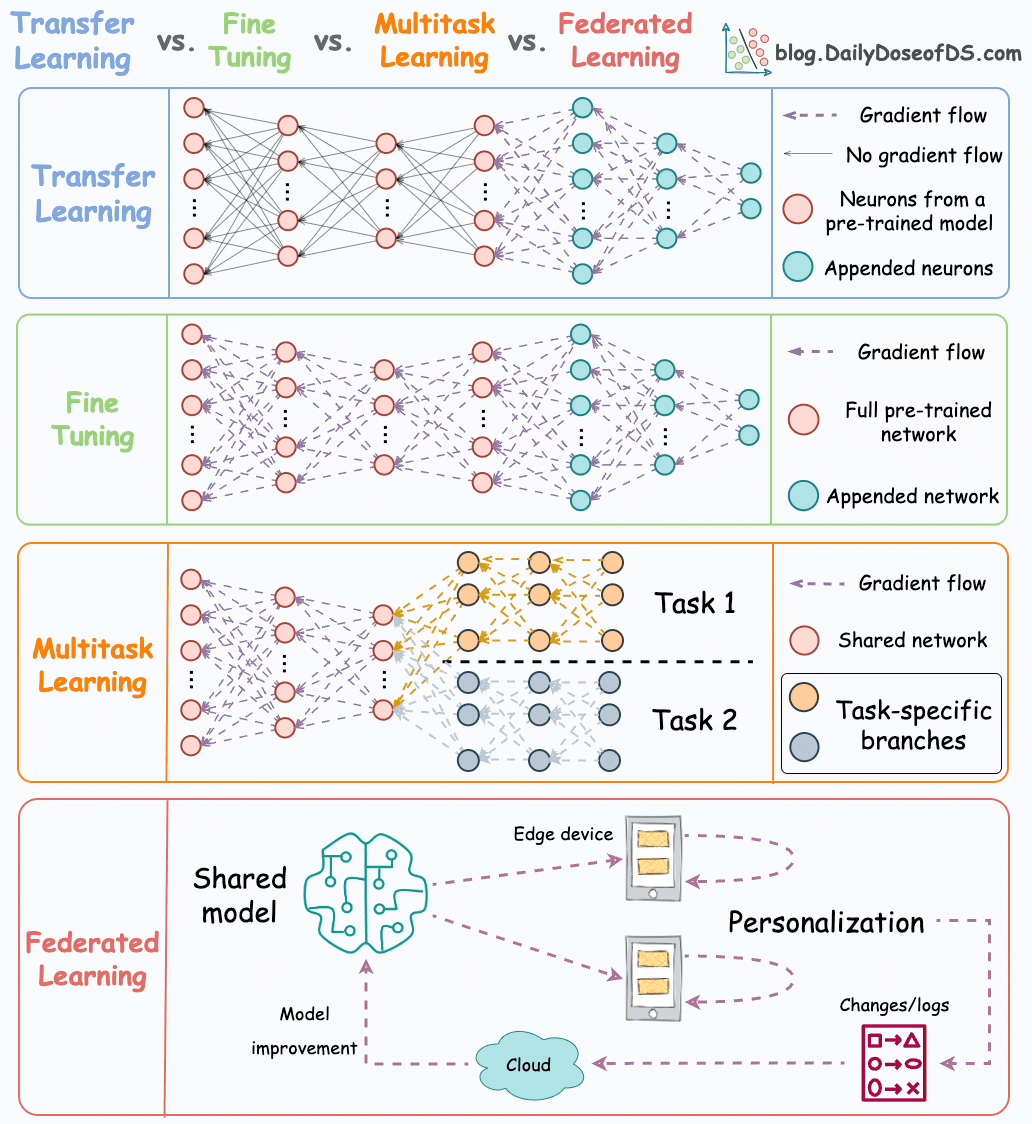
After releasing this post, a few readers showed interest in understanding how multi-task learning (MTL) is implemented in practice.
I think this is a great topic to cover because typically, most ML models are trained on one task.
As a result, many struggle to intuitively understand how a model can be trained on multiple tasks simultaneously.

So let’s discuss this today!
To reiterate, in MTL, the network has a few shared layers and task-specific segments.
During backpropagation, gradients are accumulated from all branches, as depicted in the animation below:

Let’s take a simple example to understand its implementation.
Consider we want our model to take a real value (x) as input and generate two outputs:
sin(x)cos(x)
This can be formulated as an MTL problem.
First, we define our model class using PyTorch.

As demonstrated above:
We have some fully connected layers in
self.model→ These are the shared layers.Furthermore, we have the output-specific layers to predict
sin(x)andcos(x).
This network architecture can be visually depicted as follows:

Next, let’s define the forward pass in the class above:

First, we pass the input through the shared layers (
self.model).The output of the shared layers is passed through the
sinandcosbranches.We return the output from both branches.
We are almost done.
The final part of this implementation is to train the model.
Let’s use mean squared error as the loss function.
The training loop is implemented below:

We pass the input data through the model.
It returns two outputs, one from each segment of the network.
We compute the branch-specific loss values (
loss1andloss2) using true predictions.We add the two loss values to get the total loss for the network.
Finally, we run the backward pass.
Done!
With this, we have trained our MTL model.
Also, we get a decreasing loss, which depicts that the model is being trained.
And that’s how we train an MTL model.
That was simple, wasn’t it?
You can extend the same idea to build any MTL model of your choice.
Do remember that building an MTL model on unrelated tasks will not produce good results.
Thus, “task-relatedness” is a critical component of all MTL models because of the shared layers.
Also, it is NOT necessary that every task must equally contribute to the entire network’s loss.
We may assign weights to each task as well, as depicted below:

The weights could be based on task importance.
Or…
At times, I also use dynamic task weights, which could be inversely proportional to the validation accuracy achieved on that task.
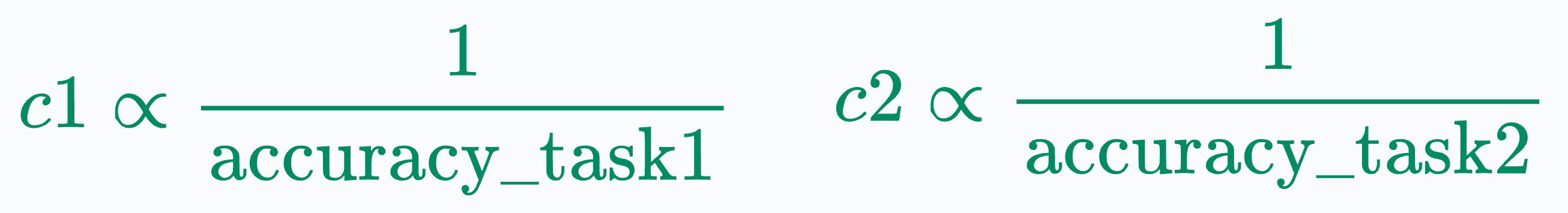
My rationale behind this technique is that in an MTL setting, some tasks can be easy while others can be difficult.
If the model achieves high accuracy on one task during training, we can safely reduce its loss contribution so that the model focuses more on the second task.
This makes intuitive sense as well.
You can download the notebook for today’s post here: Multi-task learning notebook.
And don’t forget to check out yesterday’s post in case you missed it.
👉 Over to you: What could be some other techniques to aggregate loss values of different tasks?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!