
A Practical Guide to Becoming a Deployment-Savvy Data Scientist
Take your production environment from good to great.

Last week, we learned two critical real-world ML development skills:
#1) Model compression:

We discussed four techniques to effectively reduce model size while:
Preserving model accuracy
Improving model run-time
Reducing memory usage
#2) Deploy Models directly from a Jupyter Notebook using Modelbit
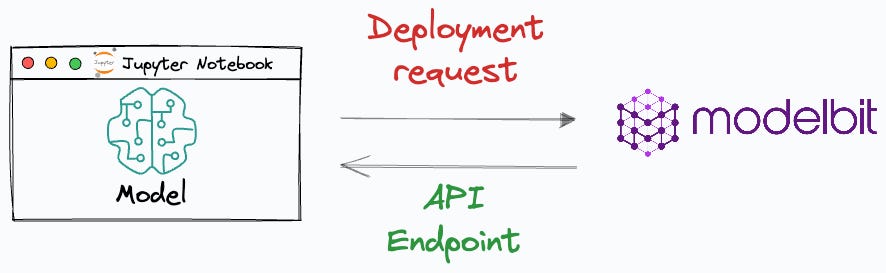
Both posts were appreciated by many of you.
So today, let’s continue our discussion on real-world ML development.
In my opinion, many think of deployment as just “deployment” — host the model somewhere, obtain an API endpoint, integrate it into the application, and you are done!
But that is almost NEVER the case.
This is because, in reality, plenty of things must be done post-deployment to ensure the model’s reliability and performance.
Let’s understand a few of them.
Version control
To begin, it is immensely crucial to version control ML deployments.
You may have noticed this while using ChatGPT, for instance. OpenAI frequently updates its model.

But updating does not simply mean overwriting the previous version.
Instead, ML models are always version-controlled (using git tools).
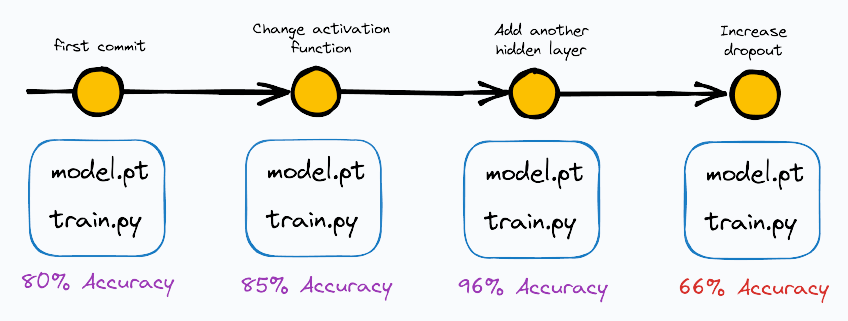
The advantages of version-controlling ML deployments are pretty obvious as well:
In case of sudden mishaps post-deployment, we can instantly roll back to an older version.
We can facilitate parallel development with branching, and many more.
Model registry
Another practical idea is to maintain a model registry for deployments.
Let’s understand what it is.
Simply put, a model registry can be considered a repository of models.

See, typically, we might be inclined to version our code and the ML model together:

However, when we use a model registry, we version models separately from the code.
Let me give you an intuitive example to understand this better.
Imagine our deployed model takes three inputs to generate a prediction:
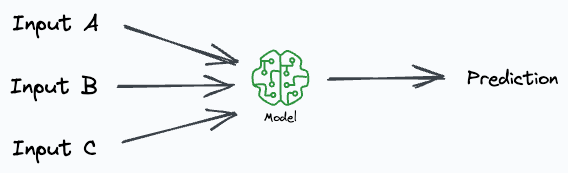
While writing the inference code, we overlooked that, at times, one of the inputs might be missing. We realized this by analyzing the model’s logs.

We may want to fix this quickly (at least for a while) before we decide on the next steps more concretely.
Thus, we may decide to update the inference code by assigning a dummy value for the missing input.

This will allow the model to still process the incoming request.
Let me ask you a question: “Did we update the model?”
No, right?
Here, we only need to update the inference code. The model will remain the same.
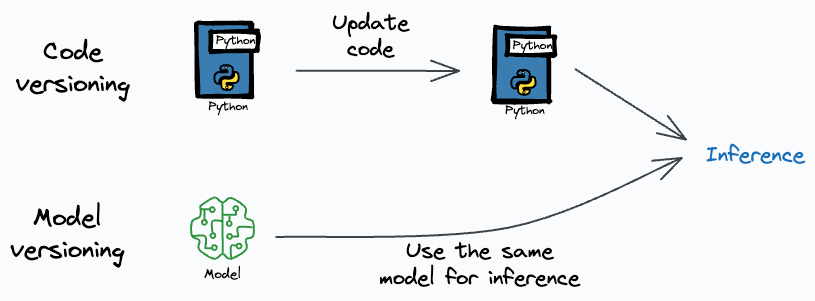
But if we were to version the model and code together, it would lead to a redundant model and take up extra space.
However, by maintaining a model registry:
We can only update the inference code.
Avoid pushing a new (yet unwanted) model to deployment.
This makes intuitive sense as well, doesn’t it?
That being said, managing models in deployment is always easier said than done.
Some relevant questions are:
What are post-deployment considerations? How to address them?
What are the challenges during deployment?
What are the challenges post-deployment?
How to practically implement version control in ML deployments?
Why is model logging critical to identify challenges like:
Performance drift
Concept drift
Covariate shift
Non-stationarity, etc.
How to practically implement and maintain a model registry?
How do we maintain ML models separately from code?
How do we deploy models to a model registry?
How to only update inference code?
How do we only update the model?
What are some major advantages of model registry?
And most importantly, how do we reliably implement end-to-end ML deployment in our projects?
Can you answer them?
If not, then this is precisely what we discussed in a recent ML deep dive: Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit.
In my opinion, deploying a model is one thing.
Maintaining, updating, and tracking is a whole other thing.
If you intend to ship reliable models to production, learning end-to-end deployment and model management is a must-know practical skill.
👉 Interested folks can read it here: Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit.
I am confident you will learn a lot of practical skills from this 30-minute deep dive :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!