
A Visual Guide to Popular Cross Validation Techniques
Cross validation techniques summarised in a single frame.


Tuning and validating machine learning models on a single validation set can be misleading at times.
While traditional validation methods, such as a single train-test split, are easy to implement, they, at times, can yield overly optimistic results.
This can occur due to a lucky random split of data which results in a model that performs exceptionally well on the validation set but poorly on new, unseen data.

That is why we often use cross-validation instead of simple single-set validation.
Cross-validation involves repeatedly partitioning the available data into subsets, training the model on a few subsets, and validating on the remaining subsets.
The main advantage of cross-validation is that it provides a more robust and unbiased estimate of model performance compared to the traditional validation method.
The image above presents a visual summary of five of the most commonly used cross-validation techniques.
Leave-One-Out Cross-Validation

Leave one data point for validation.
Train the model on the remaining data points.
Repeat for all points.
This is practically infeasible when you have tons of data points. This is because number of models is equal to number of data points.
We can extend this to Leave-p-Out Cross-Validation, where, in each iteration,
pobservations are reserved for validation and the rest are used for training.
K-Fold Cross-Validation
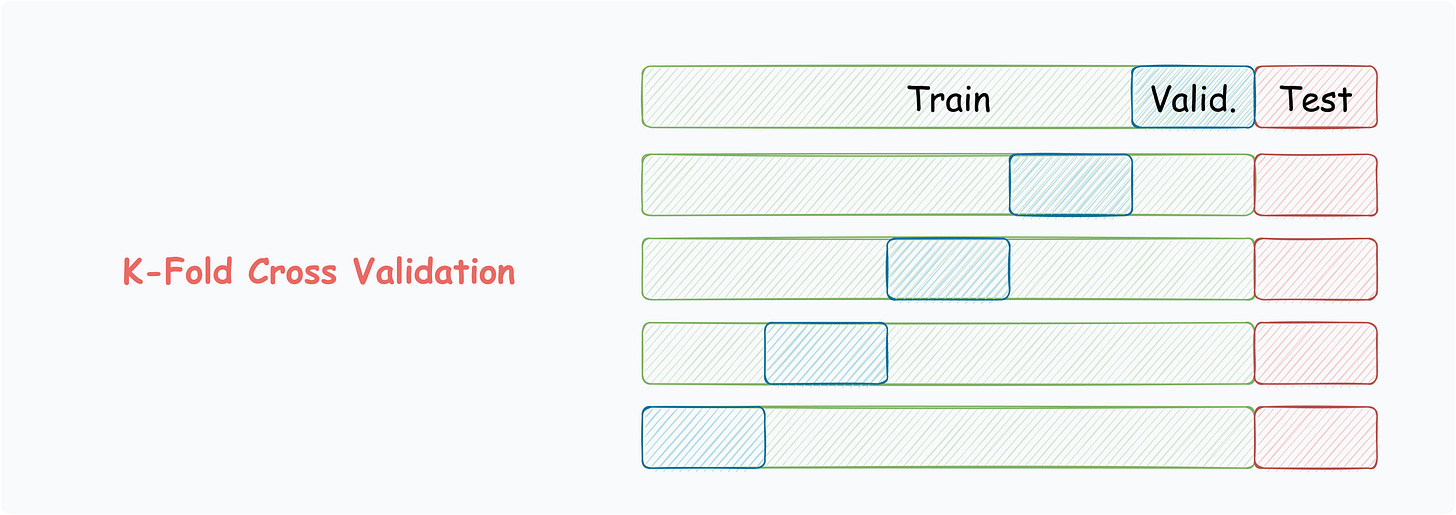
Split data into k equally-sized subsets.
Select one subset for validation.
Train the model on the remaining subsets.
Repeat for all subsets.
Rolling Cross-Validation
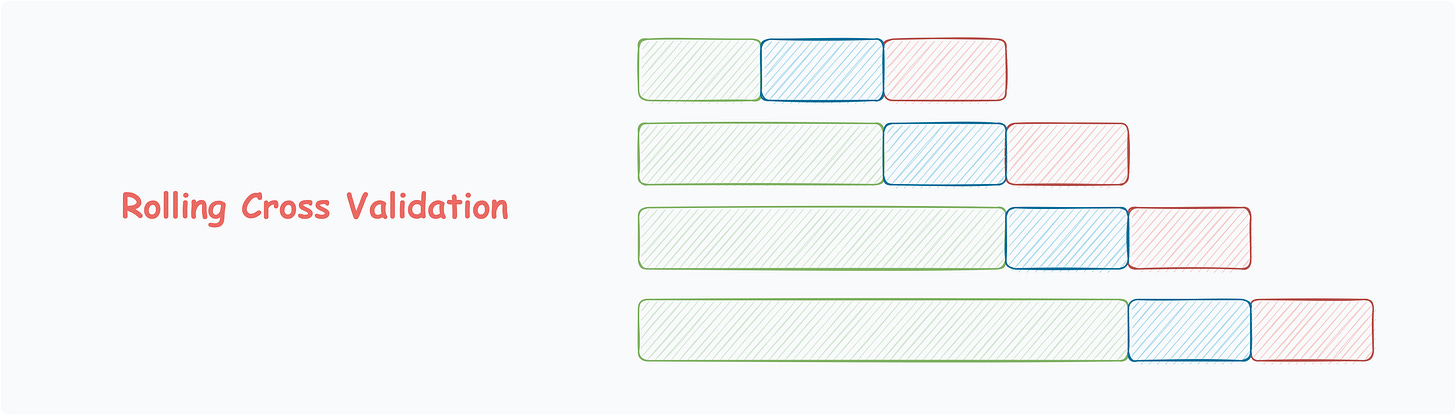
Mostly used for data with temporal structure.
Data splitting respects the temporal order, using a fixed-size training window.
The model is evaluated on the subsequent window.
Blocked Cross-Validation
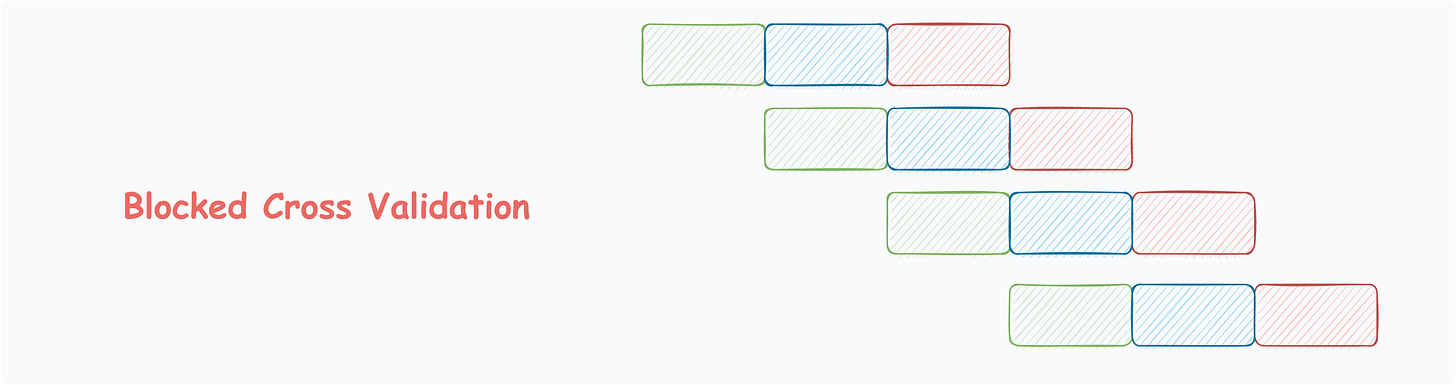
Another common technique for time-series data.
In contrast to rolling cross-validation, the slice of data is intentionally kept short if the variance does not change appreciably from one window to the next.
This also saves computation over rolling cross-validation.
Stratified Cross-Validation
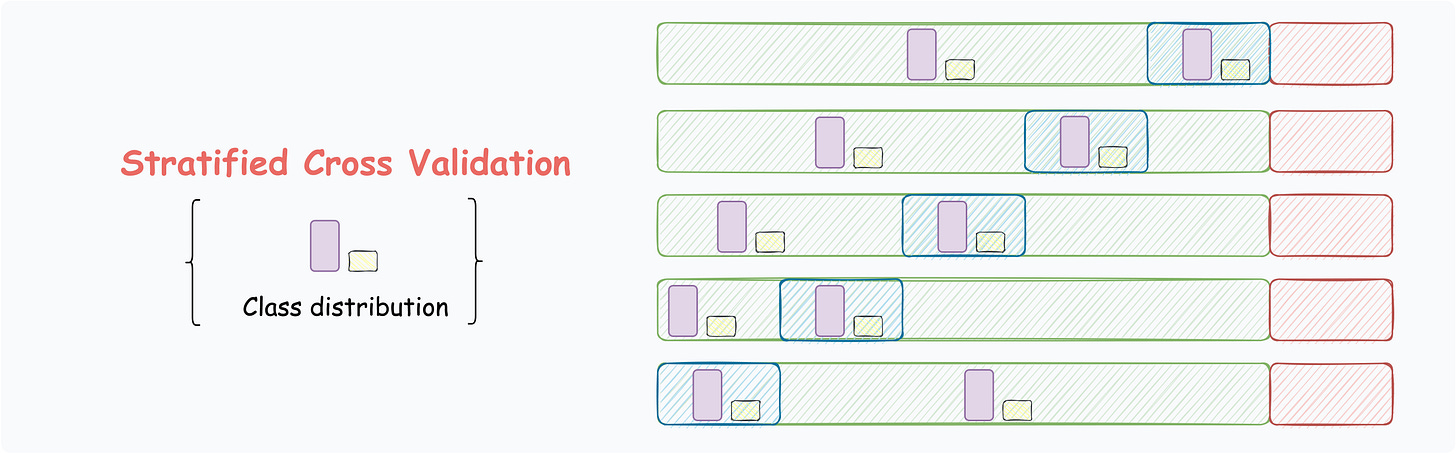
The above techniques may not work for imbalanced datasets. Thus, this technique is mostly used for preserving the class distribution.
The partitioning ensures that the class distribution is preserved.

👉 Over to you: What other cross-validation techniques have I missed?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!