
An Algorithm-wise Summary of Loss Functions in Machine Learning
Loss functions of 16 ML algorithms in a single frame.

Loss functions are a vital component of ML algorithms.
They specify the objective an algorithm should aim to optimize during its training.
In other words, loss functions explicitly tell the algorithm what it should minimize to improve its performance.
Therefore, knowing which loss functions are (typically) best suited for specific ML algorithms is extremely crucial.
The below visual depicts the most commonly used loss functions by various ML algorithms.
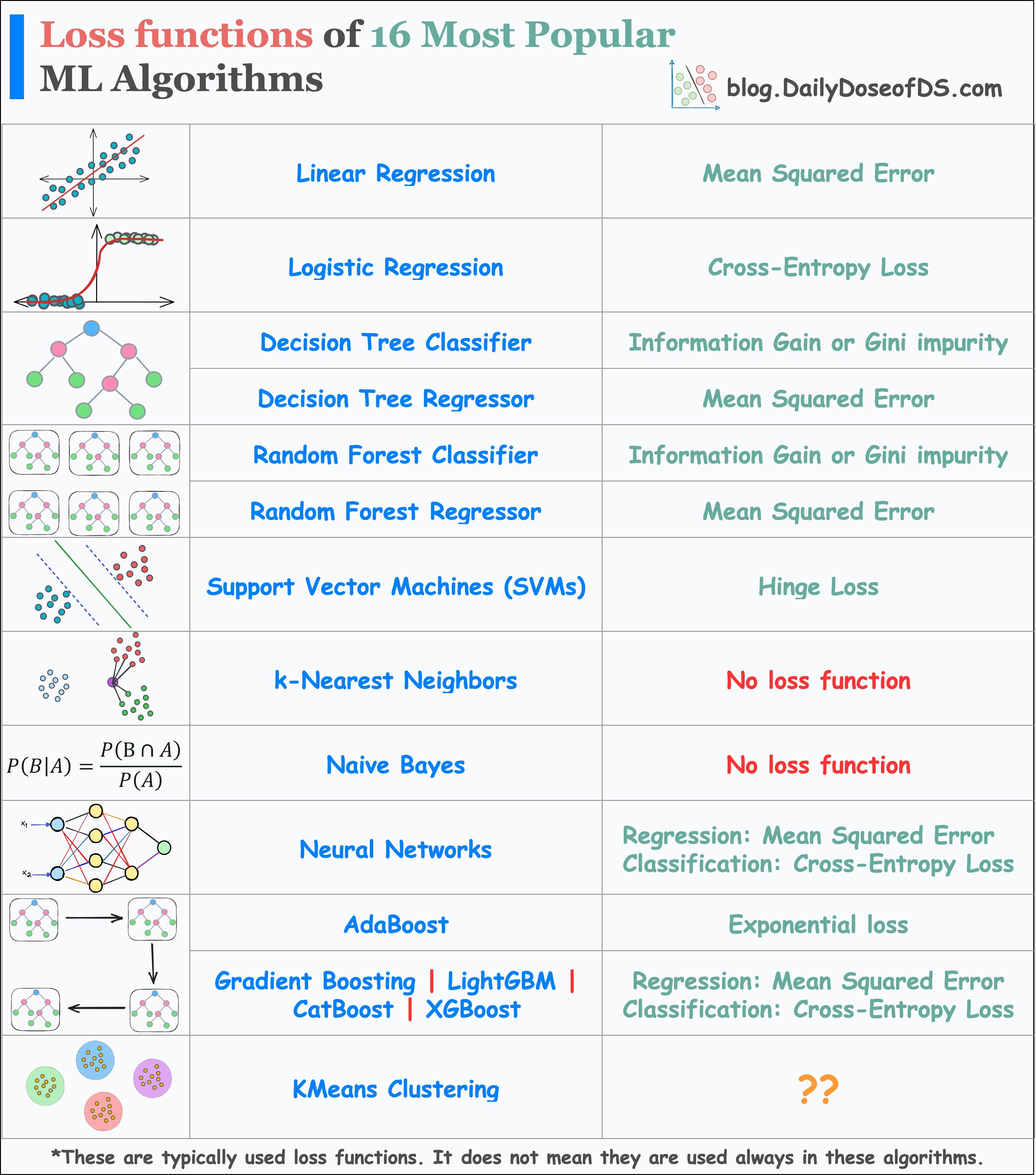
Linear Regression: Mean Squared Error (MSE). This can be used with and without regularization, depending on the situation.
Logistic regression: Cross-entropy loss or Log Loss, with and without regularization. Why log loss? We covered its origin here: Why Do We Use log-loss to Train Logistic Regression?
Decision Tree and Random Forest:
Classifier: Gini impurity or information gain.
Regressor: Mean Squared Error (MSE)
Support Vector Machines (SVMs): Hinge loss. It penalizes both wrong and right (but less confident) predictions. Best suited for creating max-margin classifiers, like in SVMs.
k-Nearest Neighbors (kNN): No loss function. kNN is a non-parametric lazy learning algorithm. It works by retrieving instances from the training data, and making predictions based on the k nearest neighbors to the test data instance.
Naive Bayes: No loss function. Can you guess why?
Neural Networks: They can use a variety of loss functions depending on the type of problem. The most common ones are:
Regression: Mean Squared Error (MSE).
Classification: Cross-Entropy Loss.
AdaBoost: Exponential loss function. AdaBoost is an ensemble learning algorithm. It combines multiple weak classifiers to form a strong classifier. In each iteration of the algorithm, AdaBoost assigns weights to the misclassified instances from the previous iteration. Next, it trains a new weak classifier and minimizes the weighted exponential loss.
Other Boosting Algorithms:
Regression: Mean Squared Error (MSE).
Classification: Cross-Entropy Loss.
👉 Over to you: Can you tell which loss function is used in KMeans?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Model Compression: A Critical Step Towards Efficient Machine Learning.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!