
An Intuitive Explanation to Maximum Likelihood Estimation (MLE) in Machine Learning
MLE: Find the most likely explanation.

When using statistical models, modeling labeled data (X, y) is about finding the specific set of model parameters (θ) that maximize the likelihood of observing the given data.
More formally, a model attempts to find the specific set of parameters (θ), which maximizes the likelihood function (L):

In simple words, the above expression says that:
maximize the likelihood of observing
ygiven
Xwhen the prediction is parameterized by some parameters
θ
When we begin modeling:
We know
X.We also know
y.The only unknown is
θ, which we are trying to determine.
This is called maximum likelihood estimation (MLE).
MLE is a method for estimating the parameters of a statistical model by maximizing the likelihood of the observed data.
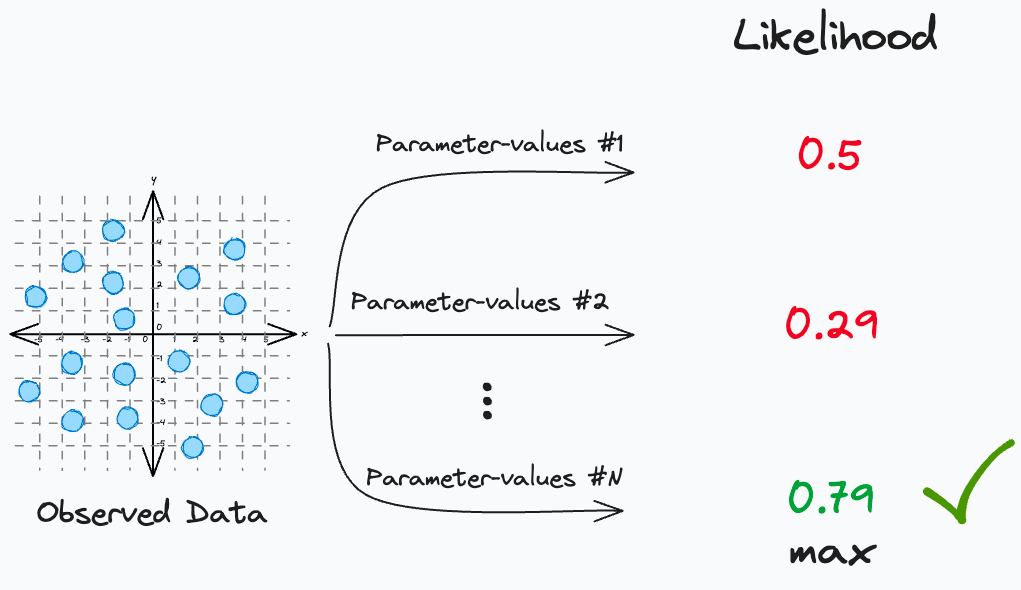
While MLE is quite popular, I have often seen many struggling to intuitively understand this critical concept.
Let’s understand this today with a real-life analogy!
Imagine you are a teacher and you conducted an exam.
Surprisingly, every student received a perfect score (20/20, say).
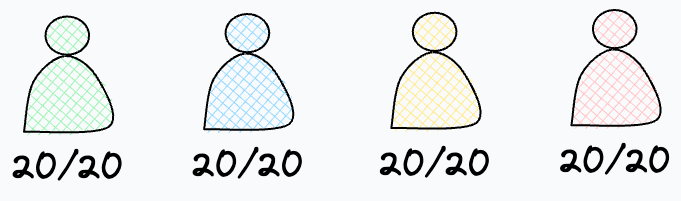
Here’s a question: “Which of these three events would have most likely happened?”
Everyone studied thoroughly for the exam.
The question paper was leaked before the exam.
The invigilator allowed the students to cheat.
Which of the above events was most likely to have happened?
In this context, one may guess that the likelihood of everyone getting a perfect score given:
“They studied thoroughly” is LOW.
“They knew the questions beforehand” is HIGH.
“The invigilator wasn’t keeping an eye on the students” is MEDIUM.

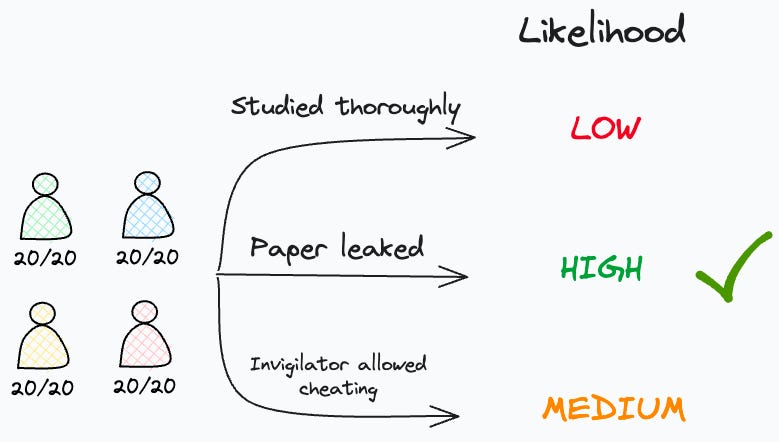
Based on this, we proceed with the event with the highest likelihood, and that’s “The question paper was leaked.”
So what did we do here?
Essentially, we maximized the conditional probability of the event (perfect score) given an explanation.

The event is what we observed — “Everyone getting a perfect score.”
An “explanation” represents a possible cause we came up with.
We formulated our problem this way because there’s a probability of:
“Perfect score” given “Everyone studied thoroughly.”
“Perfect score” given “The paper was leaked.”
“Perfect score” given “The invigilator allowed them to cheat.”
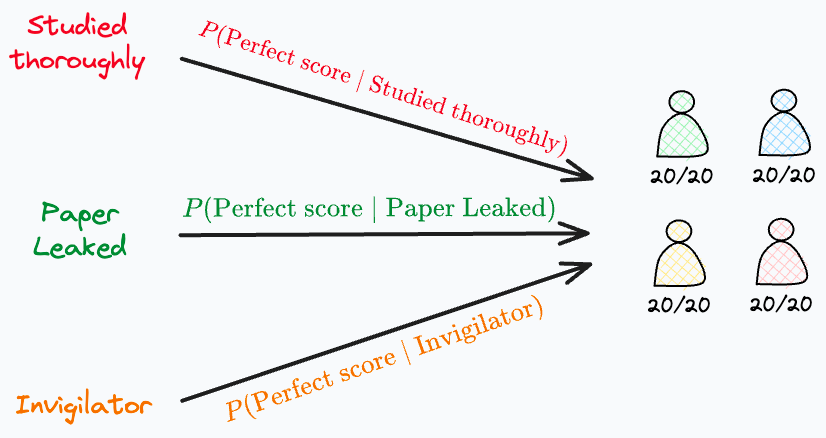
After estimating the probability, we picked the explanation with the highest conditional probability P(event|explanation).
Simply put, we tried to find the scenario that most likely led to the observed event.
That’s it.
This is the core idea behind maximum likelihood estimation (MLE).
And this is precisely what we do in machine learning at times.
We have a bunch of observed data and several models that could have possibly generated that data.

“Several models” can be thought as the same type of model but with different parameter values.
First, we estimate the probability of seeing the data given “Parameter 1”, “Parameter 2”, and so on.
Finally, we pick those parameters that most likely produced the data.

In other words, we maximize the probability of the data given parameter.
And this is called maximum likelihood estimation (MLE).
As a departing note, always remember that MLE is used to explain events that have already happened. The “event”, in this case, being the observed data.
Hope that helped :)
If you wish to learn more practical/hands-on usage of MLE, we discussed this in the following articles:
Generalized Linear Models (GLMs): The Supercharged Linear Regression
Where Did The Assumptions of Linear Regression Originate From?
👉 Over to you: What other concepts would you like to learn more intuitively?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Formulating and Implementing the t-SNE Algorithm From Scratch.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
Where Did The Assumptions of Linear Regression Originate From?
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
I find these very informative and insightful and plus getting a daily short and very well written articles helps you a lot in understanding the concepts and clearing them. It is better to learn this way. Thanks 👍