
Decision Trees ALWAYS Overfit. Here's A Lesser-Known Technique To Prevent It.
Balancing cost and model size.

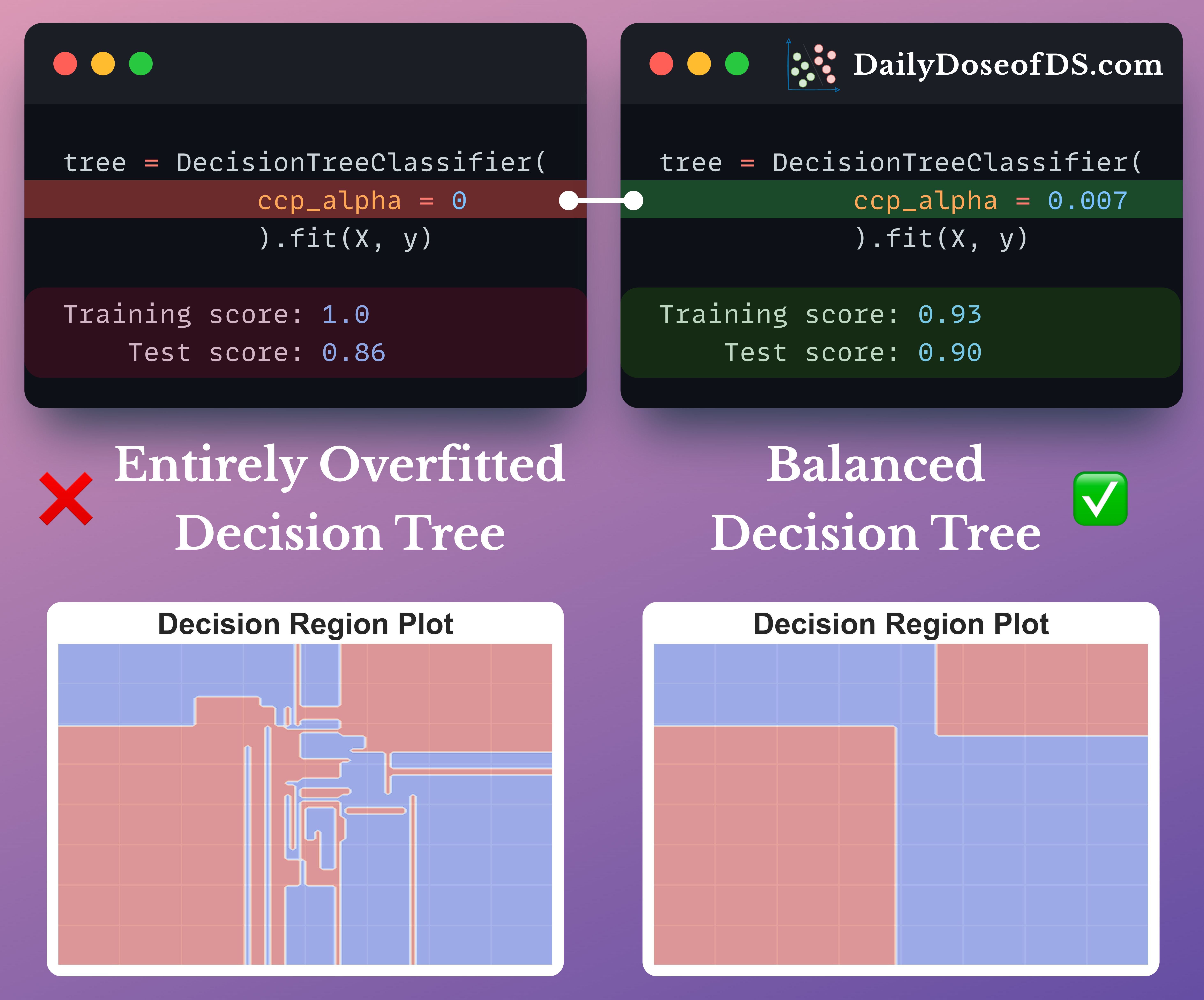
By default, a decision tree (in sklearn’s implementation, for instance), is allowed to grow until all leaves are pure.
As the model correctly classifies ALL training instances, this leads to:
100% overfitting, and
poor generalization

Cost-complexity-pruning (CCP) is an effective technique to prevent this.
CCP considers a combination of two factors for pruning a decision tree:
Cost (C): Number of misclassifications
Complexity (C): Number of nodes
The core idea is to iteratively drop sub-trees, which, after removal, lead to:
a minimal increase in classification cost
a maximum reduction of complexity (or nodes)
In other words, if two sub-trees lead to a similar increase in classification cost, then it is wise to remove the sub-tree with more nodes.

In sklearn, you can control cost-complexity-pruning using the ccp_alpha parameter:
large value of
ccp_alpha→ results in underfittingsmall value of
ccp_alpha→ results in overfitting
The objective is to determine the optimal value of ccp_alpha, which gives a better model.
The effectiveness of cost-complexity-pruning is evident from the image below:

👉 Over to you: What are some other ways you use to prevent decision trees from overfitting?
👉 Read what others are saying about this post on LinkedIn and Twitter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Sponsor the Daily Dose of Data Science Newsletter. More info here: Sponsorship details.
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
Thanks for the update. Will help learning new concepts.
That is very interesting. I always hated how Decision Trees showed overfitting when displaying decision zones. Much appreciated.