
Deploy ML Models Right from Your Jupyter Notebook Using Modelbit
Deployment has possibly never been so simple.

Yesterday’s post on model compression techniques was appreciated by many of you.
In that post, we learned four popular techniques to reduce the model size and inference run-time before deploying it.

👉 Here’s the article where we disussed them in detail along with their Python implementation: Model Compression: A Critical Step Towards Efficient Machine Learning.
Okay! So now we know how to compress a model and make it production-ready.
Next, we should also learn how to deploy it, shouldn’t we?
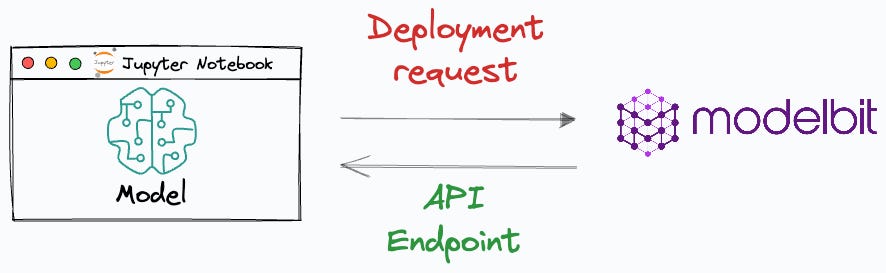
More specifically, the objective is to obtain an API endpoint for our deployed model, which can be used for inference purposes:
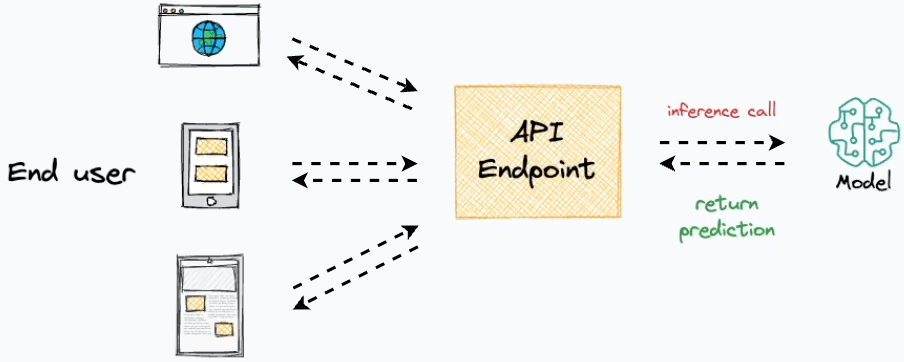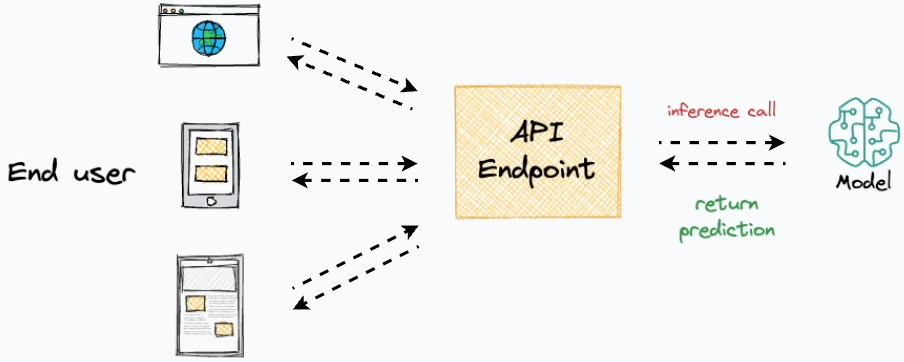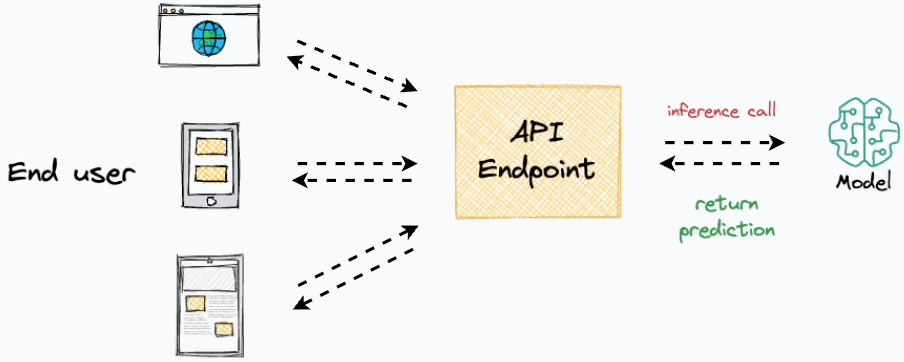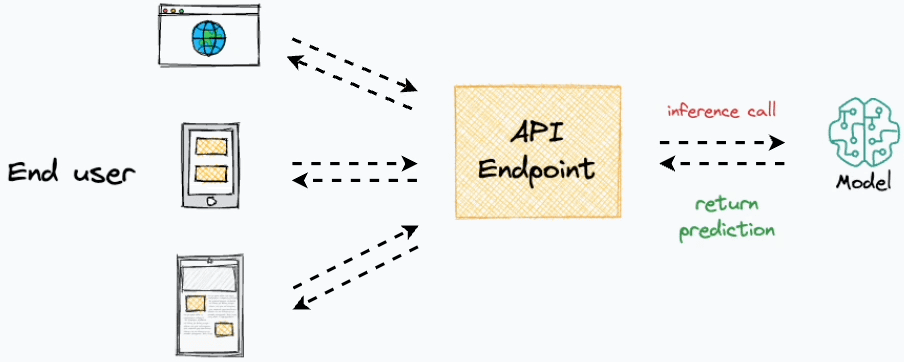
Typically, deployment is a tedious and time-consuming process.
One must maintain environment files, configure various settings, ensure all dependencies are correctly installed, and many more.
So, today, I want to help you simplify this process.
More specifically, we shall learn how to deploy any ML model right from a Jupyter Notebook in just three simple steps using the Modelbit API.
Modelbit lets us seamlessly deploy ML models directly from our Python notebooks (or git) to Snowflake, Redshift, and REST.
Assume we have already trained our model.
For simplicity, let’s assume it to be a linear regression model trained using sklearn, but it can be any other deep learning model as well:

Let’s see how we can deploy this model with Modelbit!
First, we install the Modelbit package via
pip:

Next, we log in to Modelbit from our Jupyter Notebook (make sure you have created an account here: Modelbit)

Finally, we deploy it, but here’s an important point to note:
To deploy a model using Modelbit, we must define an inference function.
Simply put, this function contains the code that will be executed at inference. Thus, it will be responsible for returning the prediction.

We must specify the input parameters required by the model in this method. Also, we can name it anything we want.
For our linear regression case, the inference function can be as follows:

We define a function
my_lr_deployment().Next, we specify the input of the model as a parameter of this method.
We validate the input for its data type.
Finally, we return the prediction.
One good thing about Modelbit is that every dependency of the function (the
modelobject in this case) is pickled and sent to production automatically along with the function. Thus, we can reference any object in this method.
Once we have defined the function, we can proceed with deployment as follows:

Done!
We have successfully deployed the model in three simple steps, that too, right from the Jupyter Notebook!
Once our model has been successfully deployed, it will appear in our Modelbit dashboard.

As shown above, Modelbit provides an API endpoint. We can use it for inference purposes as follows:
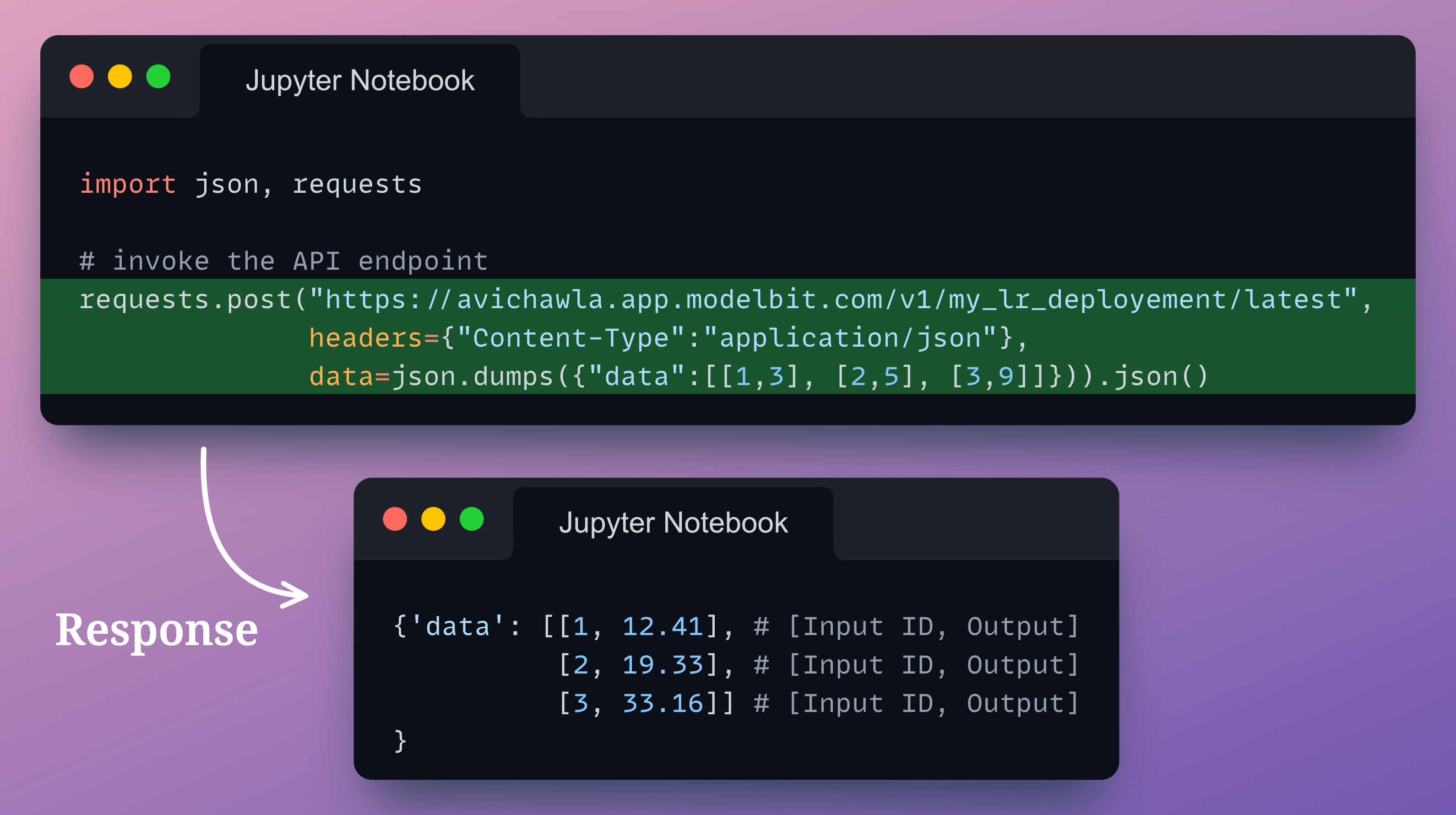
In the above request, data passed to the endpoint is a list of lists.
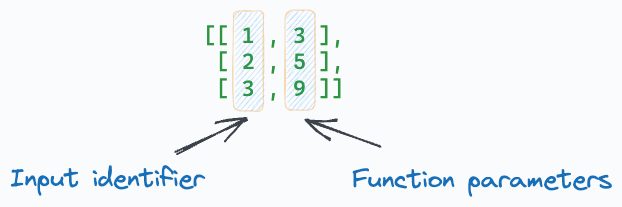
The first number in the list is the input ID. All entries following the ID in a list are the function parameters.
Lastly, we can also specify specific versions of the libraries or Python used while deploying our model. This is depicted below:

Isn’t that cool, simple, and elegant over traditional deployment approaches?
To recap, the steps are:
Connect the Jupyter kernel to Modelbit
Define the inference function
Deploy the trained model!
Try it out yourself here by downloading this Jupyter Notebook: Modelbit Deployment Notebook.
Get started with Modelbit here: Modelbit.
👉 Over to you: What are some other ways to simplify deployment?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Model Compression: A Critical Step Towards Efficient Machine Learning.
Formulating and Implementing the t-SNE Algorithm From Scratch.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
Where Did The Assumptions of Linear Regression Originate From?
To receive all full articles and support the Daily Dose of Data Science, consider subscribing: