
Does Every ML Algorithm Rely on Gradient Descent?
If not, which ones don't?

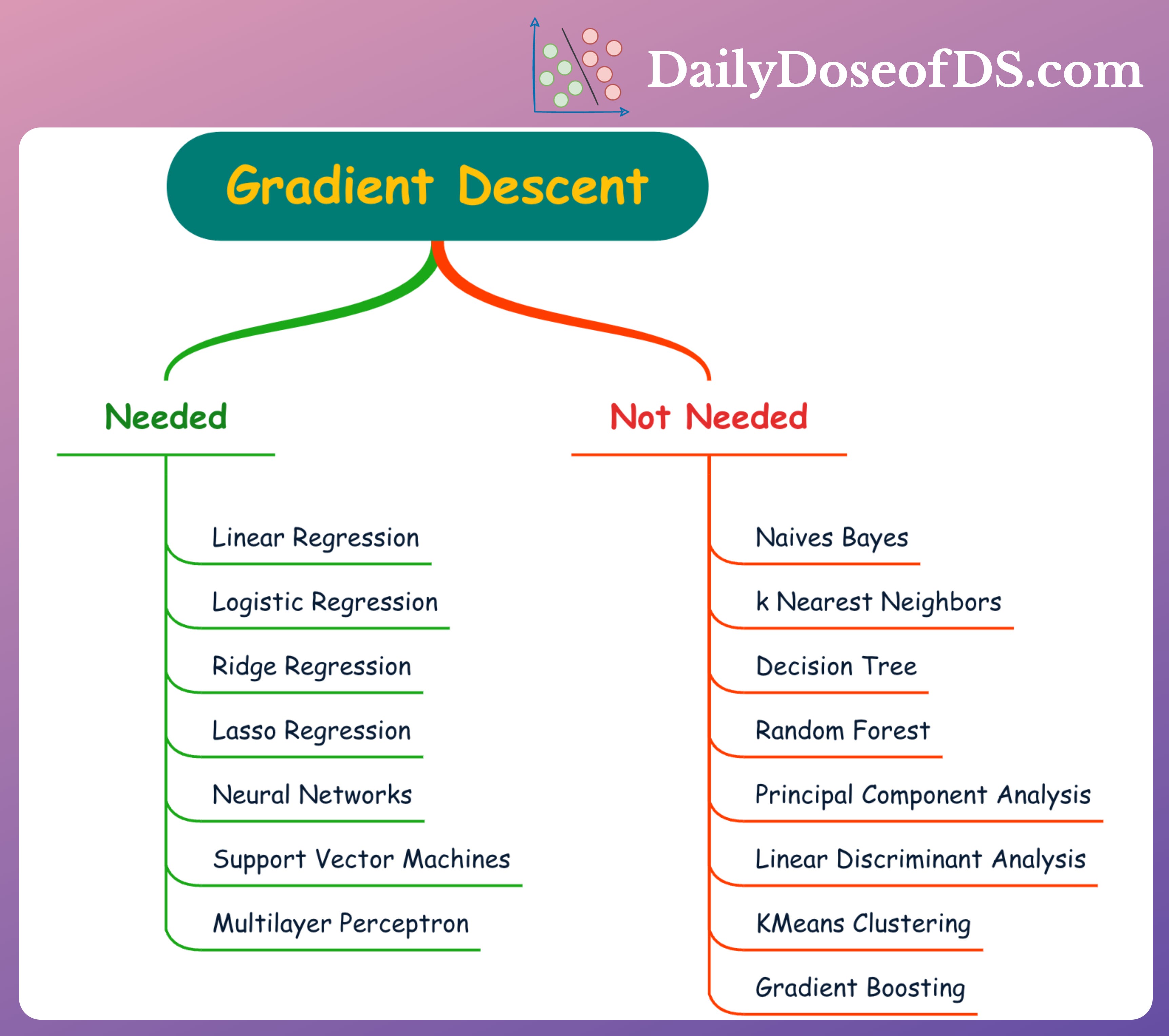
Gradient descent is the most common optimization technique in ML. Essentially, the core idea is to iteratively update the model's parameters by calculating the gradients of the cost function with respect to those parameters.
Why gradient descent is a critical technique, it is important to know that not all algorithms rely on gradient descent.
The visual above depicts this.
Algorithms that rely on gradient descent:
Linear Regression
Logistic Regression
Ridge Regression
Lasso Regression
Neural Networks (ANNs, RNNs, CNNs, LSTMs, etc.)
Support Vector Machines
Multilayer Perceptrons
Algorithms that DON’T rely on gradient descent:
Naive Bayes
kNN
Decision Tree
Random Forest
Principal Component Analysis
Linear Discriminant Analysis
KMeans Clustering
Gradient Boosting
👉 Over to you: Which algorithms have I missed?
👉 Read what others are saying about this post on LinkedIn and Twitter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
Thank you for sharing !!