
Gradient Checkpointing
An underrated technique to train larger ML models.

Neural networks primarily use memory in two ways:
Storing model weights
During training:
Forward pass to compute and store activations of all layers
Backward pass to compute gradients at each layer
This restricts us from training larger models and also limits the max batch size that can potentially fit into memory.
Gradient checkpointing is an incredible technique to reduce the memory overheads of neural nets.
Here, we run the forward pass normally and the core idea is to optimize the backpropagation step.
Let’s understand how it works.
We know that in a neural network:
The activations of a specific layer can be solely computed using the activations of the previous layer.

Forward pass

Updating the weights of a layer only depends on two things:

Backward pass The activations of that layer.
The gradients computed in the next (right) layer.

Gradient checkpointing exploits these ideas to optimize backpropagation:
Divide the network into segments before backpropagation
In each segment:
Only store the activations of the first layer.
Discard the rest of the activations.
When updating the weights of layers in a segment, recompute its activations using the first layer in that segment.
This is depicted in the image below:
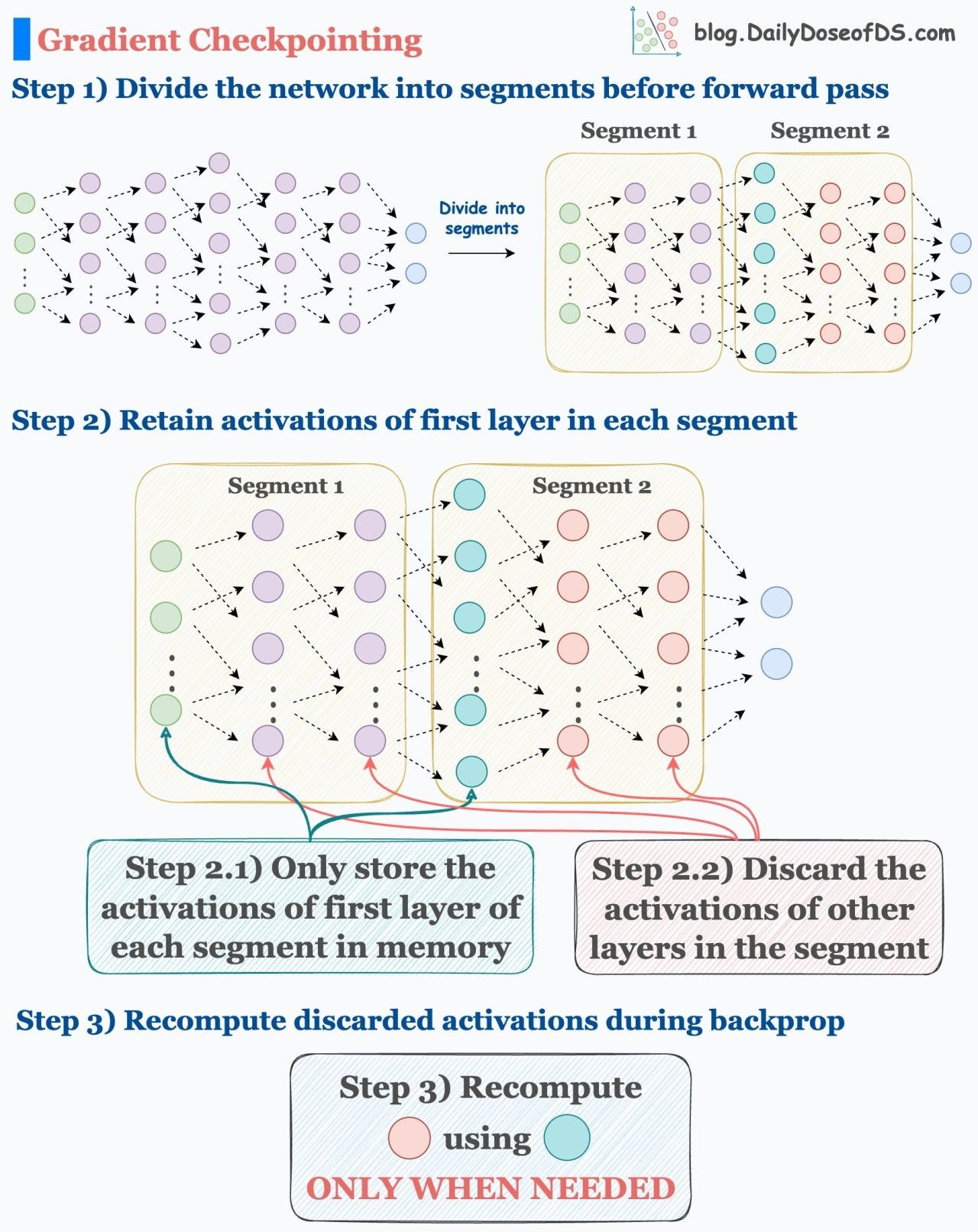
As shown above:
First, we divide the network into 2 segments.
Next, we only keep the activations of the first layer in each segment in memory.
We discard the activations of other layers in the segment.
When updating the weights of red layers, we recompute their activations using the activations of the cyan layer.

Recomputing the activations only when they are needed tremendously reduces the memory requirement.
Essentially, we don’t need to store all the intermediate activations in memory.
This allows us to train the network on larger batches of data.
Typically, gradient checkpointing can reduce memory usage by a factor of sqrt(M), where M is the memory consumed without gradient checkpointing.
The reduction is massive. But of course, due to recomputations, this does increase run-time (15-25% increases typically).
It is because we compute some activations twice.
So there's always a tradeoff between memory and run-time.
Yet, gradient checkpointing is an extremely powerful technique to train larger models without resorting to more intensive techniques like distributed training, for instance.
Thankfully, gradient checkpointing is also implemented by many open-source deep learning frameworks like Pytorch, etc.
👉 Over to you: What are some ways you use to optimize a neural network’s training?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Whenever you’re ready, here are a couple of more ways I can help you:
Get the full experience of the Daily Dose of Data Science. Every week, receive two curiosity-driven deep dives that:
Make you fundamentally strong at data science and statistics.
Help you approach data science problems with intuition.
Teach you concepts that are highly overlooked or misinterpreted.

Promote to 30,000 subscribers by sponsoring this newsletter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!