
How Zero-inflated Datasets Ruin Your Regression Modeling
...and here's how you can prevent it.

The target variable of typical regression datasets is somewhat evenly distributed.
But, at times, the target variable may have plenty of zeros. Such datasets are called zero-inflated datasets.
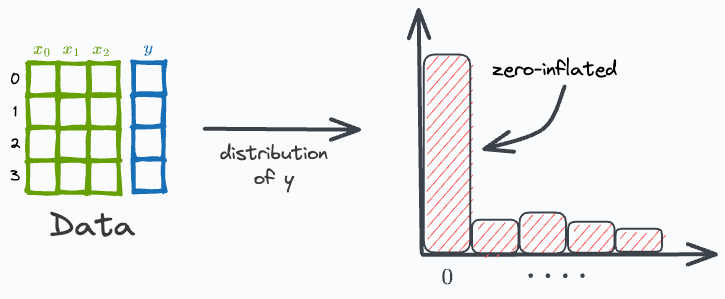
They may raise many problems during regression modeling. This is because a regression model can not always predict exact “zero” values when, ideally, it should.
For instance, consider simple linear regression. The regression line will output exactly “zero” only once (if it has a non-zero slope).

This issue persists:
Not only in higher dimensions...
But also in complex models like neural nets for regression.
One great way to solve this is by training a combination of a classification and a regression model.
This goes as follows:
Mark all non-zero targets as “1” and the rest as “0”.
Train a binary classifier on this dataset.

Next, train a regression model only on those data points with a non-zero true target.

During prediction:

If the classifier's output is “0”, the final output is also zero.
If the classifier's output is “1”, use the regression model to predict the final output.
Its effectiveness over the regular regression model is evident from the image below:
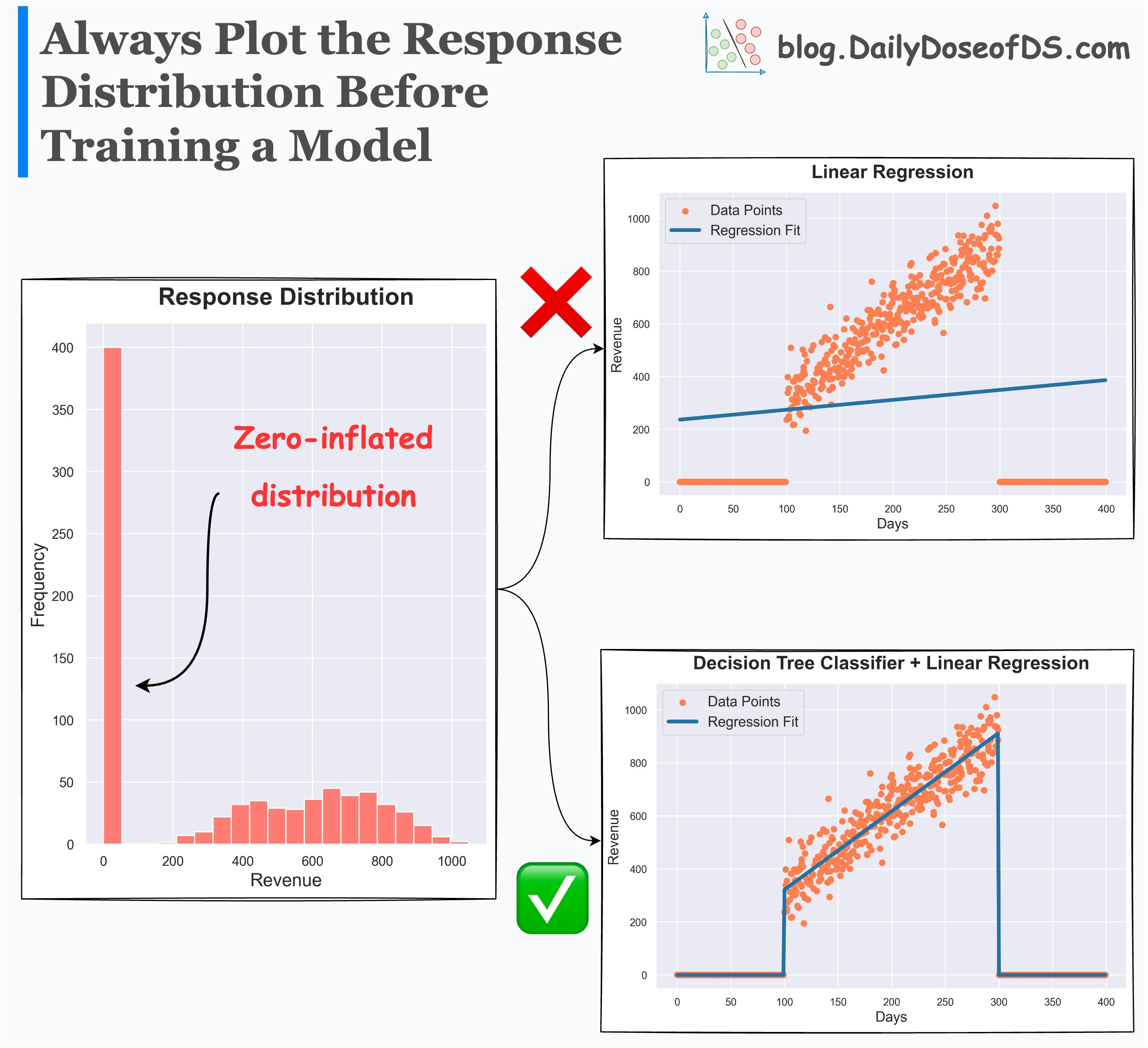
Linear regression alone underfits the data.
Linear regression with a classifier performs as expected.
👉 Over to you: What are other ways to train a model on a zero-inflated dataset?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
If you go through daily dose of data science blogs you start to feel there is a lot to know about and it is never ending. To be more precise learning data science is a continuous process and acquiring it from Daily dose of data science is the best way.
Gold.