
Interactively Visualise A Decision Tree With A Sankey Diagram
and prevent overfitting.


In one of my earlier posts, I explained why sklearn's decision trees always overfit the data with its default parameters (read here if you wish to recall).
To avoid this, it is always recommended to specify appropriate hyperparameter values. This includes the max depth of the tree, min samples in leaf nodes, etc.
But determining these hyperparameter values is often done using trial-and-error, which can be a bit tedious and time-consuming.
Here's a pretty interesting way to interactively visualize a decision tree and determine these hyperparameters:
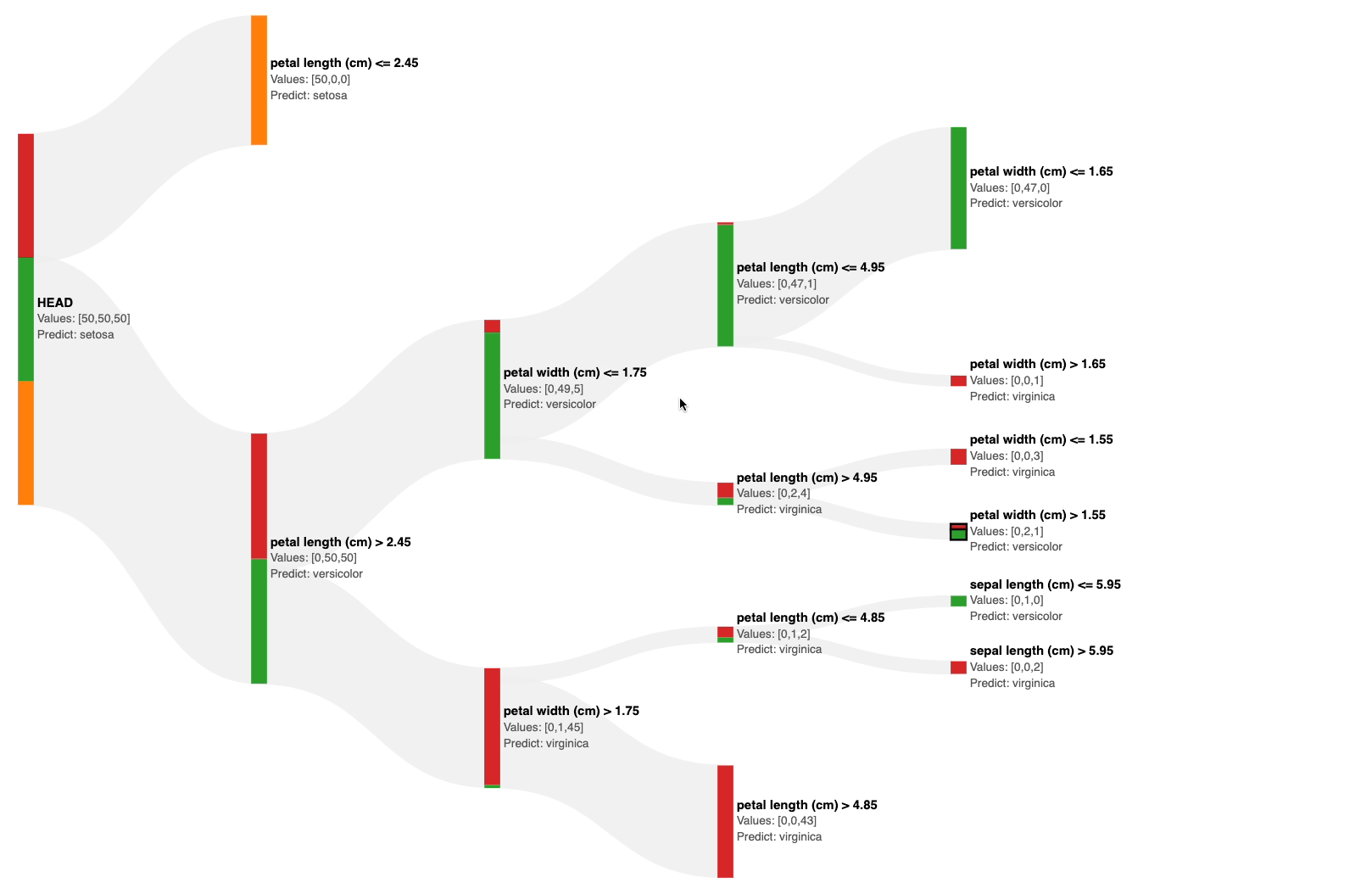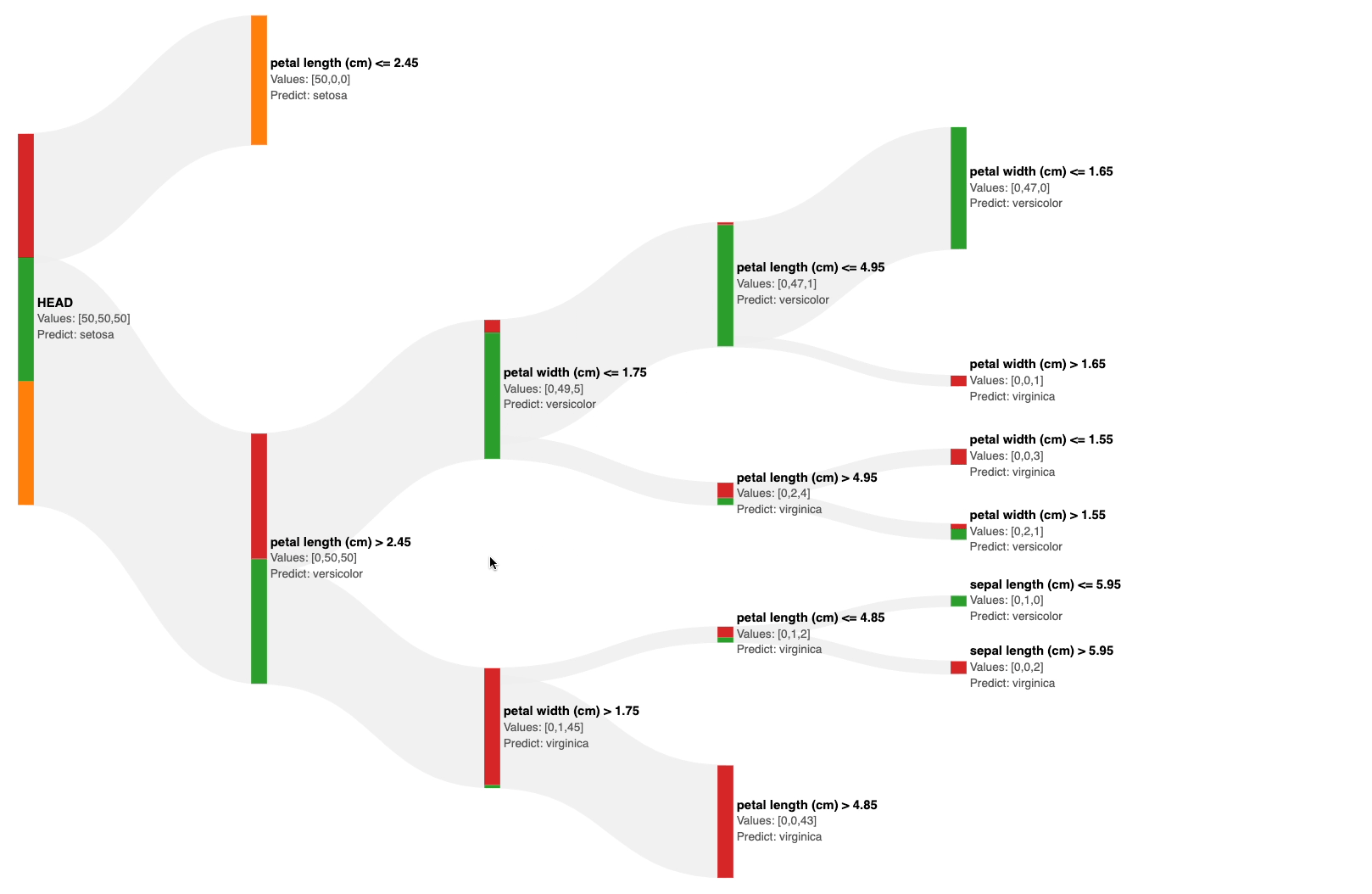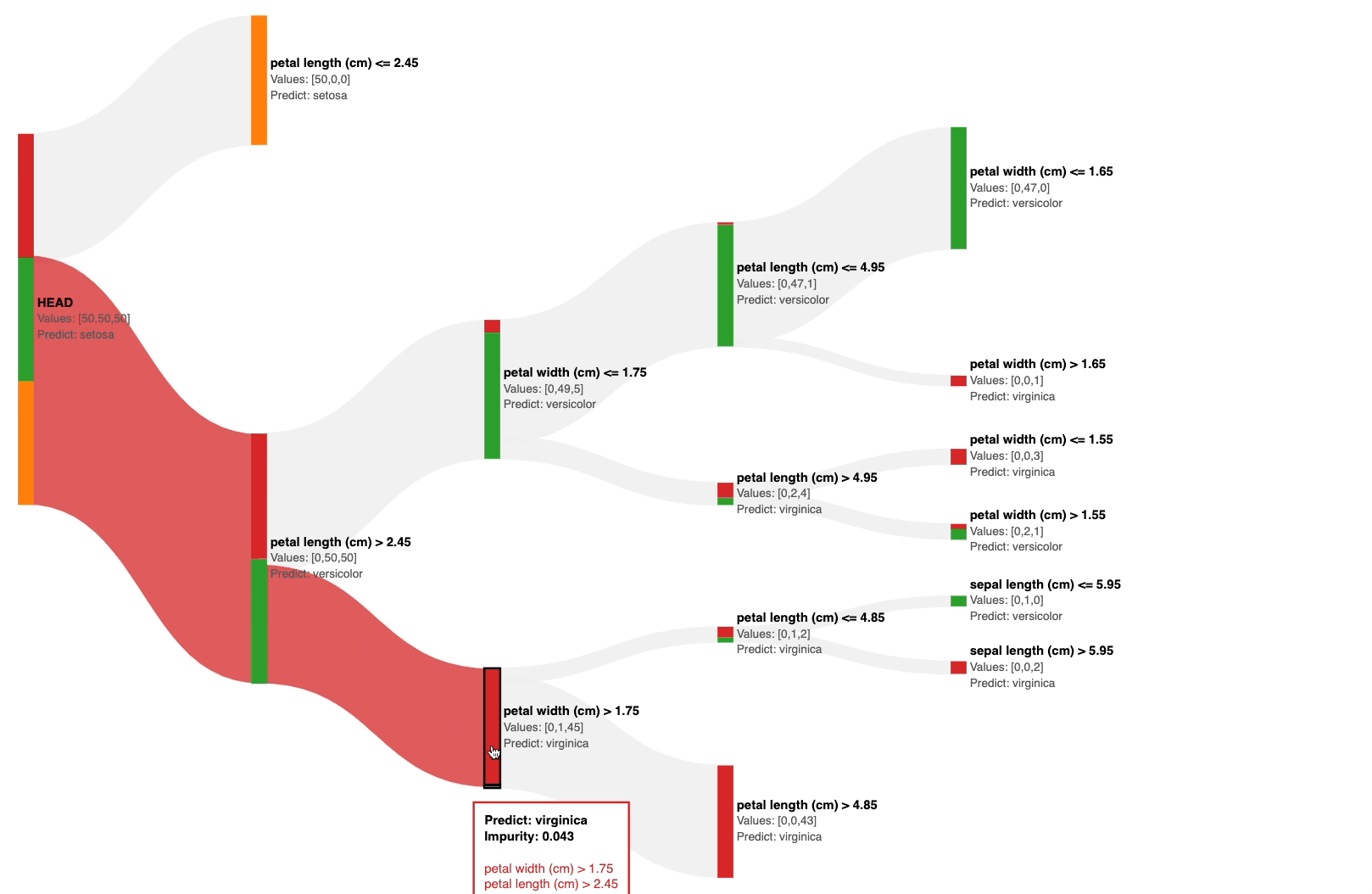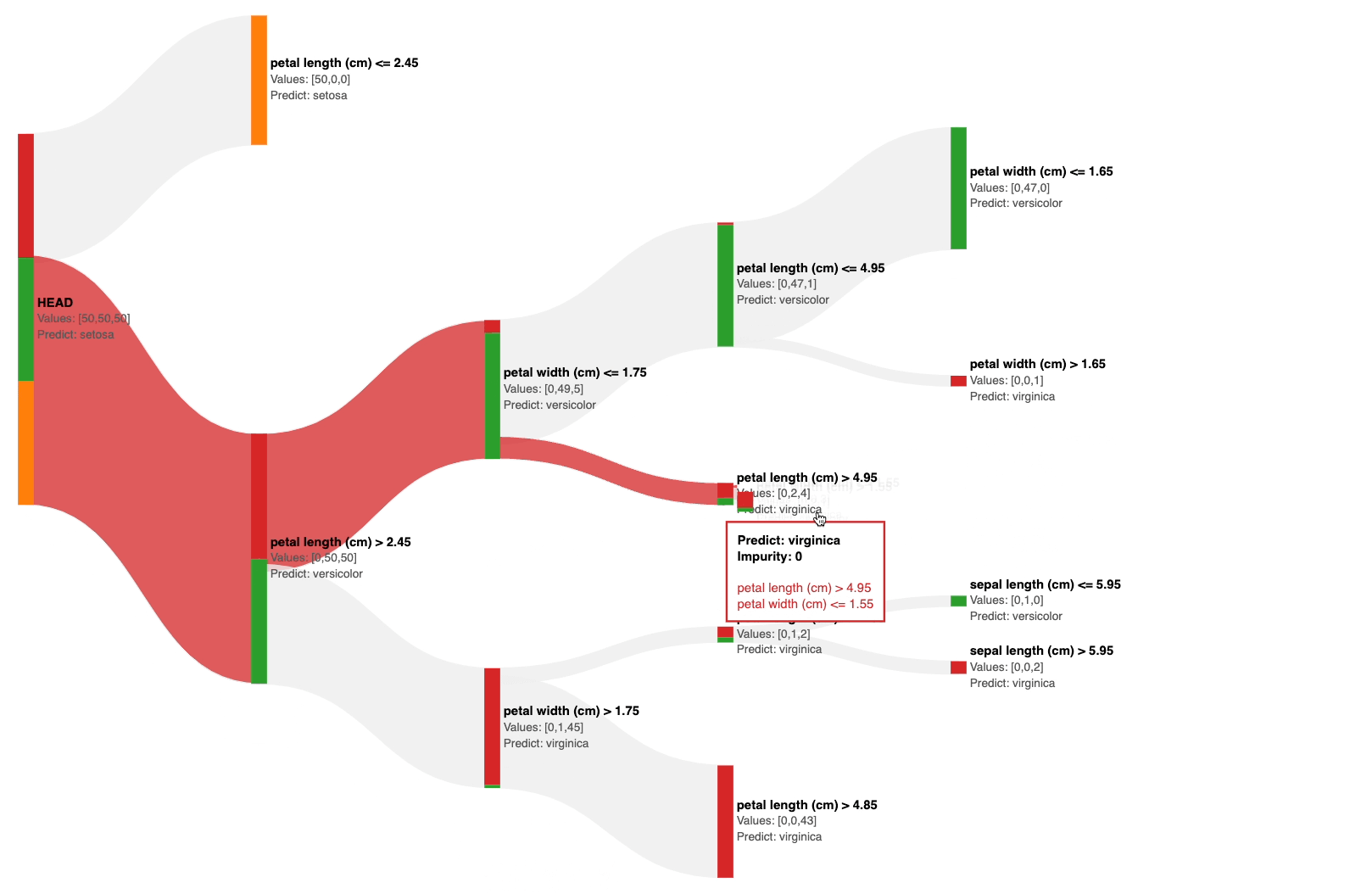
The Sankey diagram above allows you to interactively visualize the predictions of a decision tree at each node.
Also, the number of data points from each class is size-encoded on all nodes, as shown below.

This immediately gives an estimate of the impurity of the node. Based on this, you can visually decide to prune the tree.
For instance, in the full decision tree shown below, pruning the tree at a depth of two appears to be reasonable.

Once you have obtained a rough estimate for these hyperparameter values, you can train a new decision tree. Next, measure its performance on new data to know if the decision tree is generalizing or not.
Find the instructions to create this interactive visualization, along with the code here: GitHub.
👉 Read what others are saying about this post on LinkedIn.
👉 Tell me you liked this post by leaving a heart react ❤️.
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
Excellent