
Is Class Imbalance Always A Big Problem To Deal With?
May be not.


Addressing class imbalance is often a challenge in ML. Yet, it may not always cause a problem. Here's why.
One key factor in determining the impact of imbalance is class separability.
As the name suggests, it measures the degree to which two or more classes can be distinguished or separated from each other based on their feature values.
When classes are highly separable, there is little overlap between their feature distributions (as shown below). This makes it easier for a classifier to correctly identify the class of a new instance.
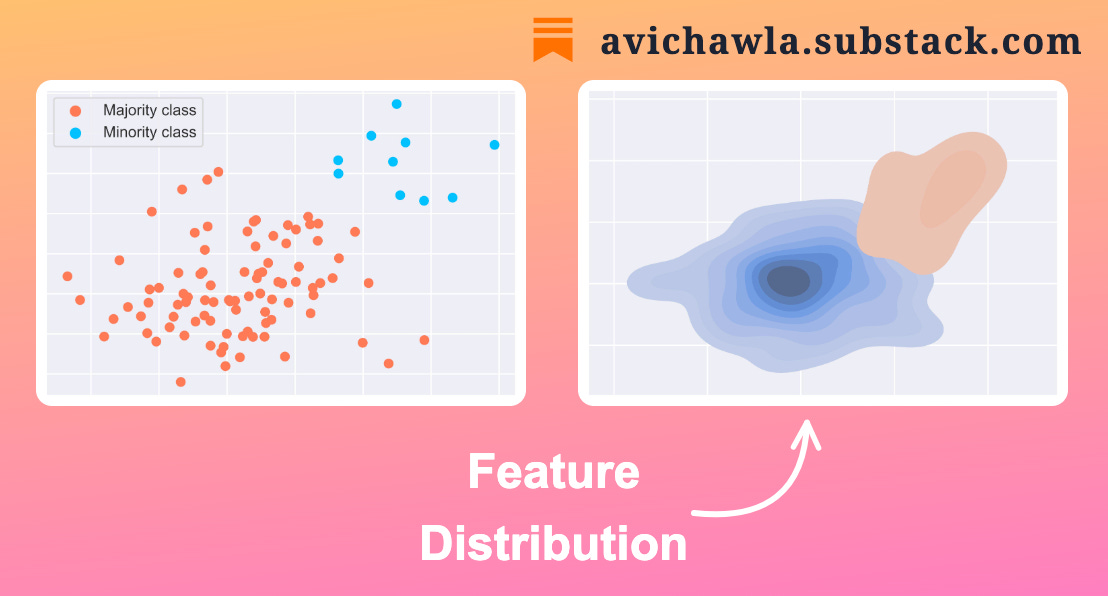
However, when classes are poorly separable, their feature distributions overlap (as shown below). This makes it challenging for a classifier to accurately distinguish between them.

Thus, despite imbalance, even if your data has a high degree of class separability, imbalance may not be a problem per se.
To conclude, consider estimating the class separability before jumping to any sophisticated modeling steps.
This can be done visually or by evaluating imbalance-specific metrics on simple models.
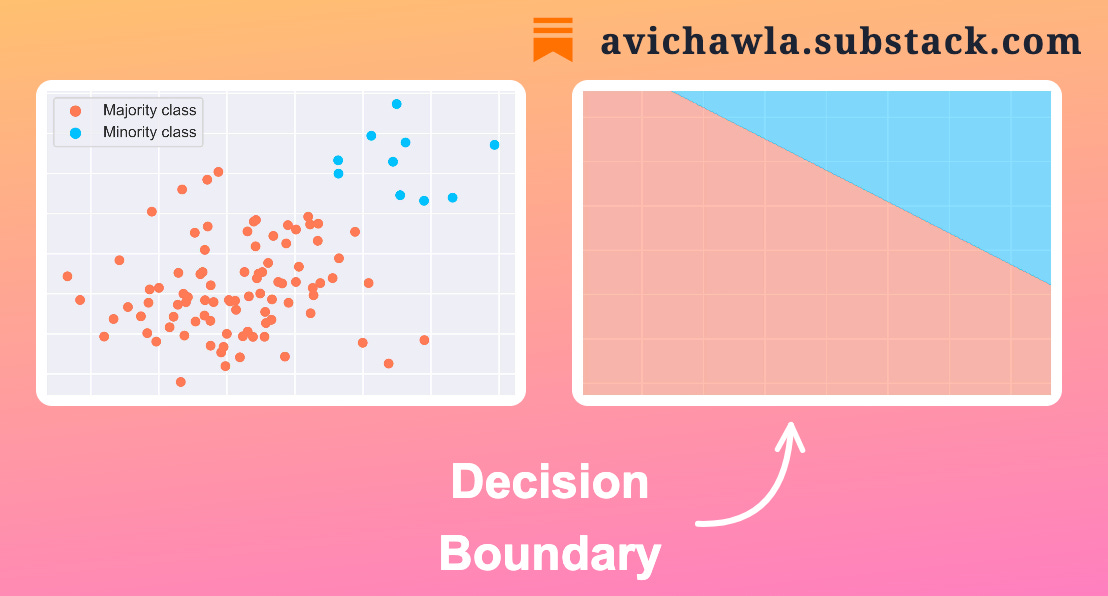
The figure below depicts the decision boundary learned by a logistic regression model on the class-separable dataset.
👉 Tell me you liked this post by leaving a heart react 🤍.
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
Good one !