
Measure Similarity Between Two Probability Distributions using Bhattacharyya Distance
...And how it differs from KL divergence.

At times, assessing how similar two probability distributions are is quite helpful.
For instance, imagine we have a labeled dataset (X, y).
By analyzing the label (y) distribution, we may hypothesize its distribution before modeling.
We also looked at this in a recent deep dive into generalized linear models (GLMs).
Read it here if you haven’t yet: Generalized Linear Models (GLMs): The Supercharged Linear Regression.
While visual inspection is often helpful, this approach is quite subjective and may lead to misleading conclusions.

Thus, it is essential to be aware of quantitative measures as well.
Bhattacharyya distance is one such reliable measure.
It quantifies the similarity between two probability distributions.
The core idea is to approximate the overlap between two distributions, which measures the “closeness” between the two distributions under consideration.
Bhattacharyya distance between two probability distributions is measured as follows:
For two discrete probability distributions:

For two continuous probability distributions (replace summation with an integral):

Its effectiveness is evident from the image below.

Here, we have an observed distribution (Blue). Next, we measure its distance from:
Gaussian distribution → 0.19.
Gamma distribution → 0.03.
A high Bhattacharyya distance indicates less overlap or more dissimilarity. This lets us conclude that the observed distribution resembles a Gamma distribution.
Also, the results resonate with visual inspection.
KL Divergence vs. Bhattacharyya distance
Now, many often get confused between KL Divergence and Bhattacharyya distance.
Effectively, both are quantitative measures to determine the “similarity” between two distributions.
However, their notion of “similarity” is entirely different.
The core idea behind KL Divergence is to assess how much information is lost when one distribution is used to approximate another distribution.
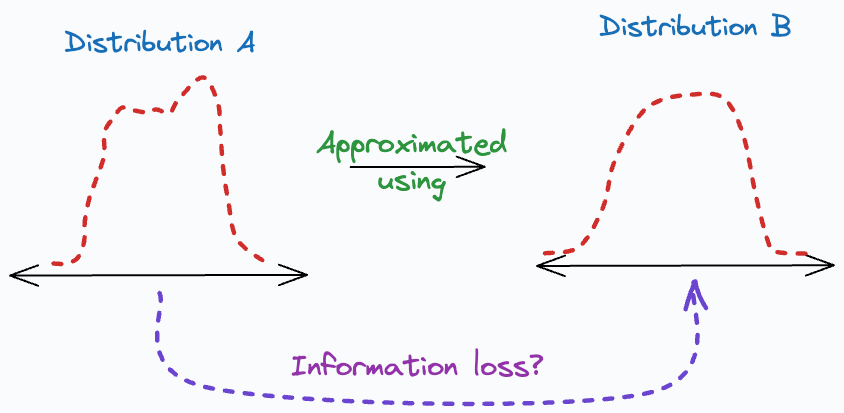
The more information is lost, the more the KL Divergence and, consequently, the less the “similarity”.
Also, approximating a distribution Q using P may not be the same as doing the reverse — P using Q.
This makes KL Divergence asymmetric in nature.
Moving on, Bhattacharyya distance measures the overlap between two distributions.

This “overlap” is often interpreted as a measure of closeness (or distance) between the two distributions under consideration.
Thus, Bhattacharyya distance primarily serves a distance metric, like Euclidean, for instance.
Being a distance metric, it is symmetric in nature. We can also verify this from the distance formula:
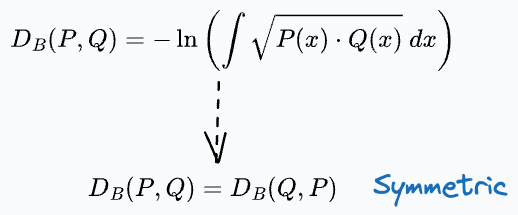
Just like we use Euclidean distance to report the distance between two points, we can use Bhattacharyya distance to report the distance between two probability distributions.

But if we intend to measure the amount of information lost when we approximate one distribution using another, KL divergence is more apt.
In fact, KL divergence also serves as a loss function in machine learning algorithms at times. Here’s how:
Say we have an observed distribution (P) and want to approximate it with another simpler distribution Q.
So, we can define a simpler parametric distribution Q.
Next, we can measure the information lost by approximating P using Q with KL divergence.
As we want to minimize the information lost, we can use KL divergence as our objective function.
Finally, we can use gradient descent to determine the parameters of Q such that we minimize the KL divergence.
For instance, KL divergence is used as a loss function in the t-SNE algorithm. We discussed it here: t-SNE article.
Bhattacharyya distance has many applications, not just in machine learning but in many other domains.
For instance:
Using this distance, we can simplify complex distributions to simple ones if the distance is low.
In image processing, Bhattacharyya distance is often used for image matching. By comparing the color or texture distributions of images, it helps identify similar objects or scenes.
And many more.
👉 Over to you: What other measures do you use in such situations?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading :)
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Model Compression: A Critical Step Towards Efficient Machine Learning.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
The Bhattacharyya distance does not satisfy the triangle inequality, so technically it is not a distance metric. The Hellinger distance may be more appropriate depending on the situation.