
Shuffle Feature Importance: Let Chaos Decide Which Features Matter the Most
An intuitive and reliable technique to measure feature importance.

Understanding feature importance is critical for the interpretability of ML models.

Of the many techniques, I often find “Shuffle Feature Importance” to be a pretty handy and intuitive technique to measure feature importance.
Let’s understand this today!
As the name suggests, it observes how shuffling a feature influences the model performance.
The visual below illustrates this technique in four simple steps:
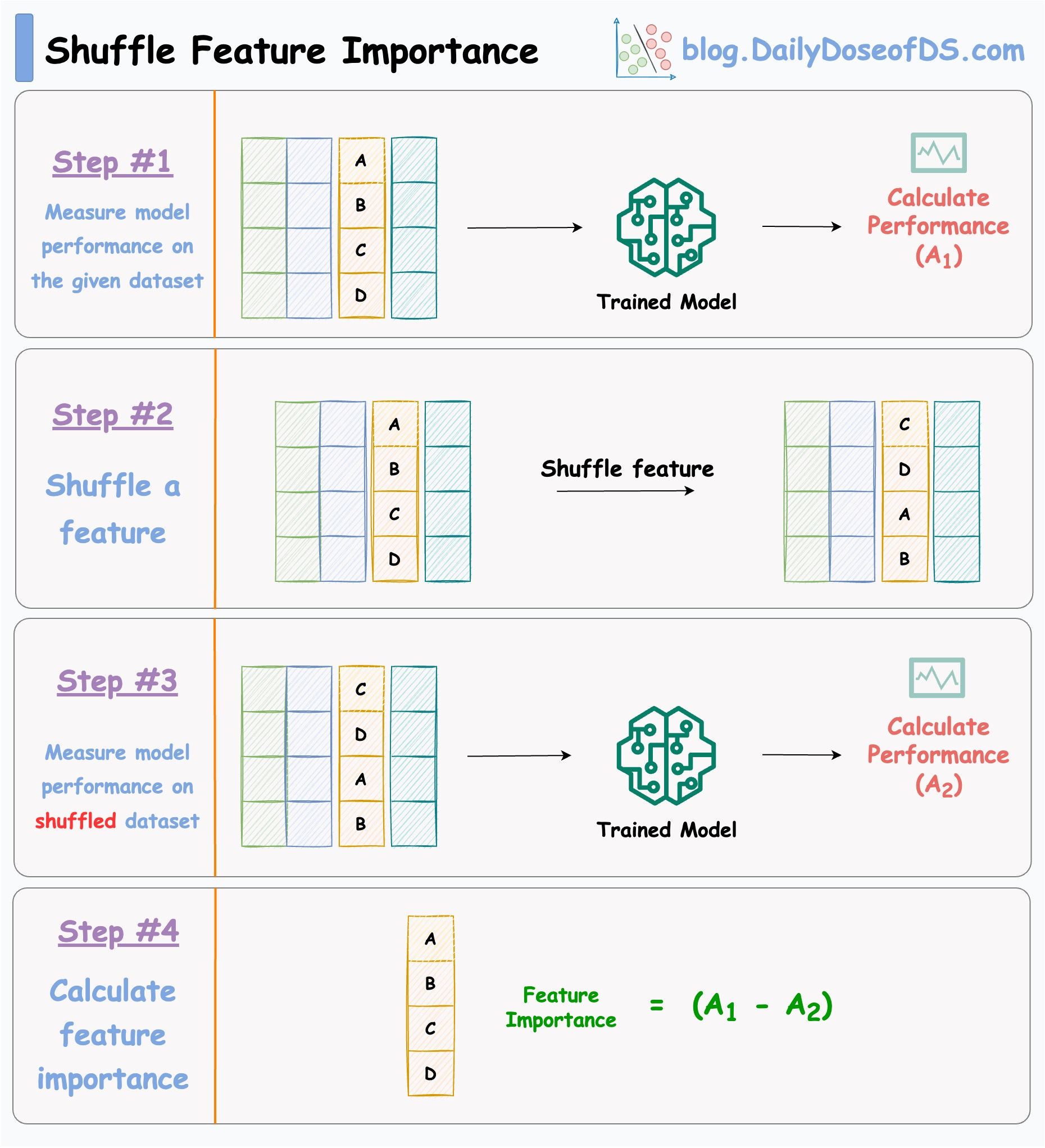
After training a model, we do the following:
Measure model performance (
A1) on the given dataset (test/validation/train).Shuffle one feature randomly.
Measure performance (
A2) again.Feature importance can be measured using performance drop = (
A1-A2).Repeat for all features.
This makes intuitive sense as well, doesn’t it?
Simply put, if we randomly shuffle just one feature and everything else stays the same, then the performance drop will indicate how important that feature is.

If the performance drop is low → This means that the feature has a very low influence on the model’s predictions.
If the performance drop is high → This means that the feature has a very high influence on the model’s predictions.
Do note that to eliminate any potential effects of randomness during feature shuffling, it is recommended to:
Shuffle the same feature multiple times
Measure average performance drop.
A few things that I love about this technique are:
It requires no repetitive model training. Just train the model once and measure the feature importance.
It is pretty simple to use and quite intuitive to interpret.
This technique can be used for all ML models that can be evaluated.
Of course, there is one caveat as well.
Say two features are highly correlated, and one of them is permuted/shuffled.
In this case, the model will still have access to the feature through its correlated feature.

This will result in a lower importance value for both features.
One way to handle this is to cluster highly correlated features and only keep one feature from each cluster.
👉 Over to you: What other reliable feature importance techniques do you use frequently?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Let's see if I understand this. You say "Simply put, if we randomly shuffle just one feature and everything else stays the same..." Are you saying, you shuffle ONLY one column (feature) in the dataset, correct? This means after the shuffle, the dataset would no longer be valid, since the observations will no longer match the original observations. But I'm thinking this is okay if the "shuffled" observations are only used to determine feature importance, and are not used for modeling. Correct? Please comment.
I agree. You're absolutely right about that according to quantum theory.