
Supercharge Your Jupyter Kernel With ipyflow
Addressing some pain points of the default kernel.

This is a pretty cool jupyter hack I learned recently.
While using Jupyter, you must have noticed that when you update a variable, all its dependent cells have to be manually re-executed.
Also, at times, isn't it difficult to determine the exact sequence of cell executions that generated an output?
This is tedious and can get time-consuming if the sequence of dependent cells is long.
To resolve this, try 𝐢𝐩𝐲𝐟𝐥𝐨𝐰. It is a supercharged kernel for jupyter, which tracks the relationship between cells and variables.

Thus, at any point, you can obtain the corresponding code to reconstruct any symbol.
What's more, its magic command enables an automatic recursive re-execution of dependent cells if a variable is updated.
As shown in the demo above, updating the variable x automatically triggers its dependent cells.
Do note that 𝐢𝐩𝐲𝐟𝐥𝐨𝐰 offers a different kernel from the default kernel in Jupyter. Thus, once you install 𝐢𝐩𝐲𝐟𝐥𝐨𝐰, select the following kernel while launching a new notebook:
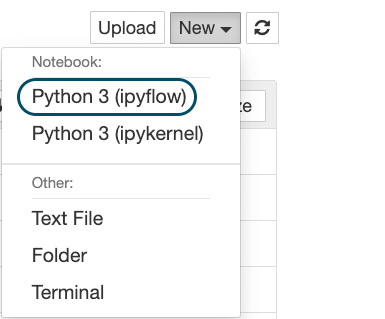
Find more details here: ipyflow.
👉 Read what others are saying about this post on LinkedIn.
👉 Tell me you liked this post by leaving a heart react ❤️.
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.