
The First Step to Feature Scaling is NOT Feature Scaling
Approaching feature scaling the right way.

Feature scaling is commonly used to improve the performance and stability of ML models.
This is because it scales the data to a standard range. This prevents a specific feature from having a strong influence on the model’s output.
For instance, in the image above, the scale of income could massively impact the overall prediction. Scaling both features to the same range can mitigate this and improve the model’s performance.
I am sure you already know this, so we won’t get into more detail here.
However, have you ever wondered the following:
Is feature scaling always necessary when our dataset’s features have a diverse range?
In my opinion, while feature scaling is often crucial, we often overlook whether it is even needed or not.
This is because many ML algorithms are unaffected by scale.
This is evident from the image below, which depicts the test accuracy of some classification algorithms with and without feature scaling:
As shown above:
Logistic regression (trained using SGD), SVM Classifier, MLP, and kNN do better with feature scaling.
Decision trees, Random forests, Naive bayes, and Gradient boosting are unaffected by scale.
To understand better, consider a decision tree, for instance.
It splits the data based on thresholds determined solely by the feature values, regardless of their scale.
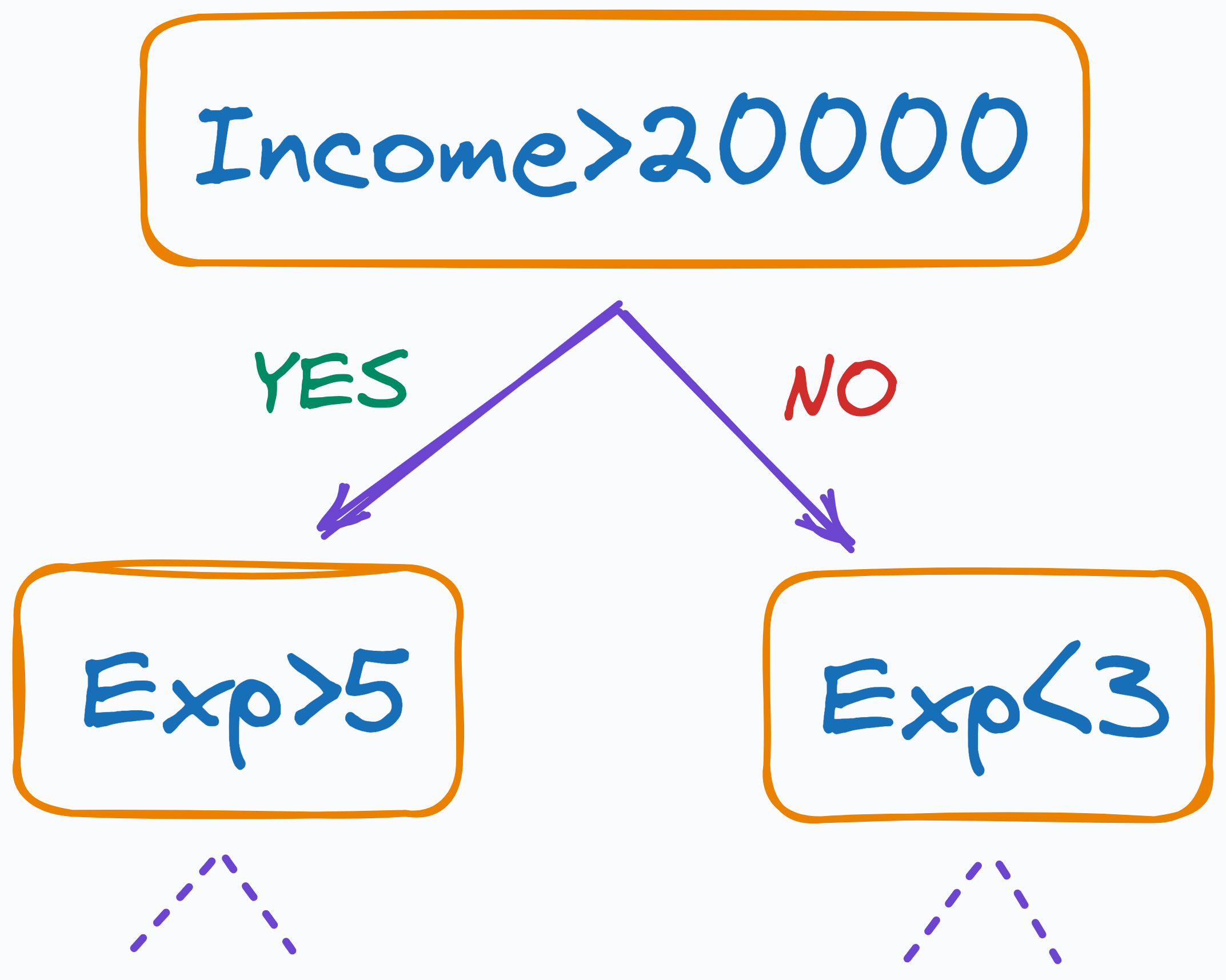
As a result, its performance is unaffected by the scale.
This makes intuitive sense as well.
Thus, the takeaway is that when we do feature scaling, it’s important to understand not just the nature of our data but also the algorithm we intend to use.
We may never need feature scaling if the algorithm is insensitive to the scale of the data.
Along the same lines is yet another common data science practice: Missing data imputation.
After seeing missing values in a dataset, most people jump directly into imputing them.
But as counterintuitive as it may sound, the first step towards imputing missing data should NEVER be imputation.
Read this newsletter issue to learn more about it: The First Step Towards Missing Data Imputation Must NEVER be Imputation.
👉 Over to you: What other algorithms typically work well without scaling data?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
That's one problem we got wrong at my startup. We started implementing as many features as we could. The best is to focus features on your mission and ROI.
In another words, whenever you are using distance based optimisation function, do the feature scaling.