
The Limitation Of Euclidean Distance Which Many Often Ignore
...And a possible alternative to look for.


Euclidean distance is a commonly used distance metric. Yet, its limitations often make it inapplicable in many data situations.
Euclidean distance assumes independent axes, and the data is somewhat spherically distributed. But when the dimensions are correlated, euclidean may produce misleading results.
Mahalanobis distance is an excellent alternative in such cases. It is a multivariate distance metric that takes into account the data distribution.
As a result, it can measure how far away a data point is from the distribution, which Euclidean can not.
As shown in the image above, Euclidean considers pink and green points equidistant from the central point. But Mahalanobis distance considers the green point to be closer, which is indeed true, taking into account the data distribution.
Mahalanobis distance is commonly used in outlier detection tasks. As shown below, while Euclidean forms a circular boundary for outliers, Mahalanobis, instead, considers the distribution—producing a more practical boundary.
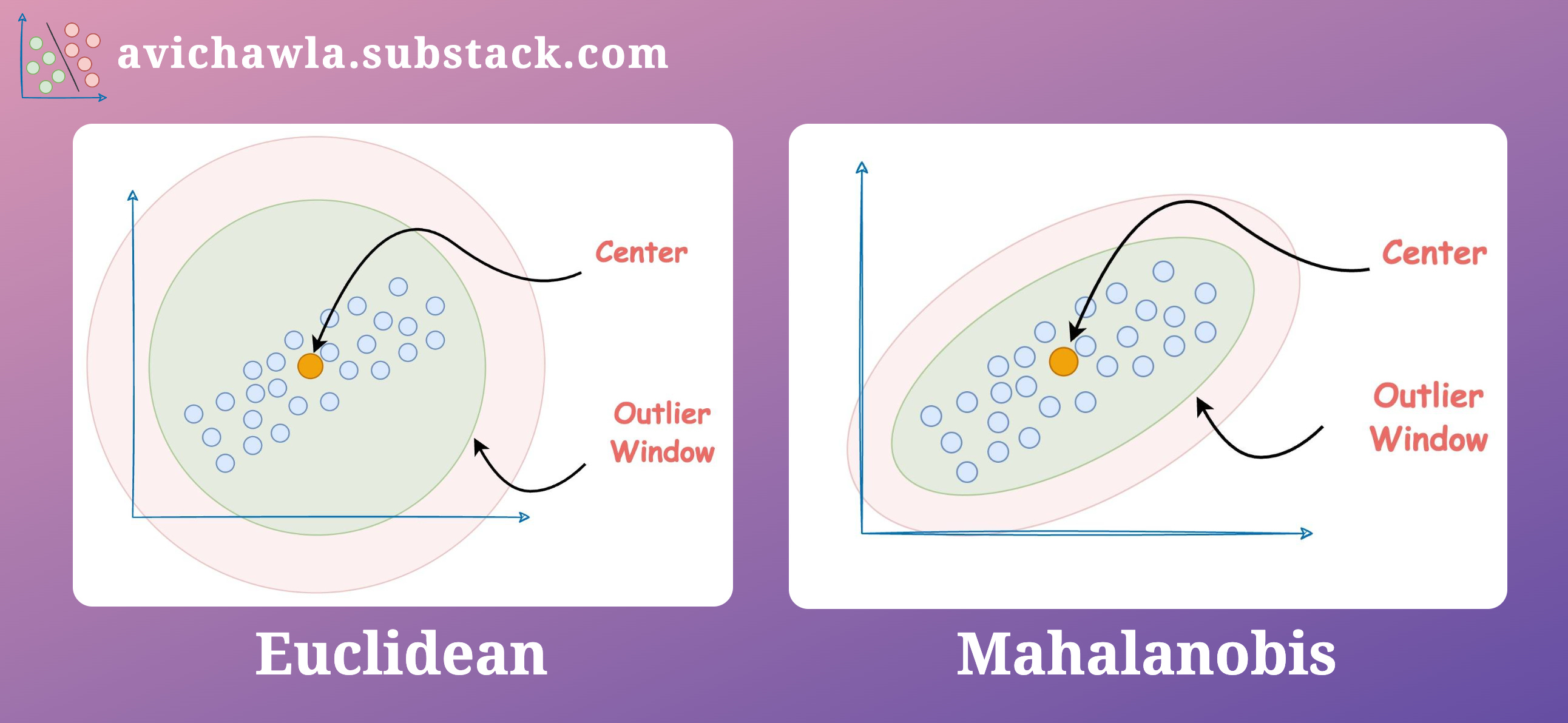
Essentially, Mahalanobis distance allows the data to construct a coordinate system for itself, in which the axes are independent and orthogonal.
Computationally, it works as follows:
Step 1: Transform the columns into uncorrelated variables.
Step 2: Scale the new variables to make their variance equal to 1.
Step 3: Find the Euclidean distance in this new coordinate system, where the data has a unit variance.
So eventually, we do reach Euclidean. However, to use Euclidean, we first transform the data to ensure it obeys the assumptions.
Mathematically, it is calculated as follows:

x: rows of your dataset (Shape:
n_samples*n_dimensions).μ: mean of individual dimensions (Shape:
1*n_dimensions).C^-1: Inverse of the covariance matrix (Shape:
n_dimensions*n_dimensions).D^2: Square of the Mahalanobis distance (Shape:
n_samples*n_samples).
Find more info here: Scipy docs.
👉 Read what others are saying about this post on LinkedIn.
👉 Tell me you liked this post by leaving a heart react ❤️.
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.