
The Limitation of Static Embeddings Which Made Them Obsolete
A visual guide to context-aware embeddings.


To build models for language-oriented tasks, it is crucial to generate numerical representations (or vectors) for words.

This allows words to be processed and manipulated mathematically and perform various computational operations on words.
The objective of embeddings is to capture semantic and syntactic relationships between words. This helps machines understand and reason about language more effectively.
In the pre-Transformers era, this was primarily done using pre-trained static embeddings.
Essentially, someone would train and release these word embeddings for, say, 100k, or 200k common words using deep learning.
…and other researchers may utilize those embeddings in their projects.
The most popular models at that time (around 2013-2018ish) were:
Glove
Word2Vec
FastText, etc.
These embeddings genuinely showed some promising results in learning the relationships between words.
For instance, running the vector operation (King - Man) + Woman would return a vector near the word “Queen”.
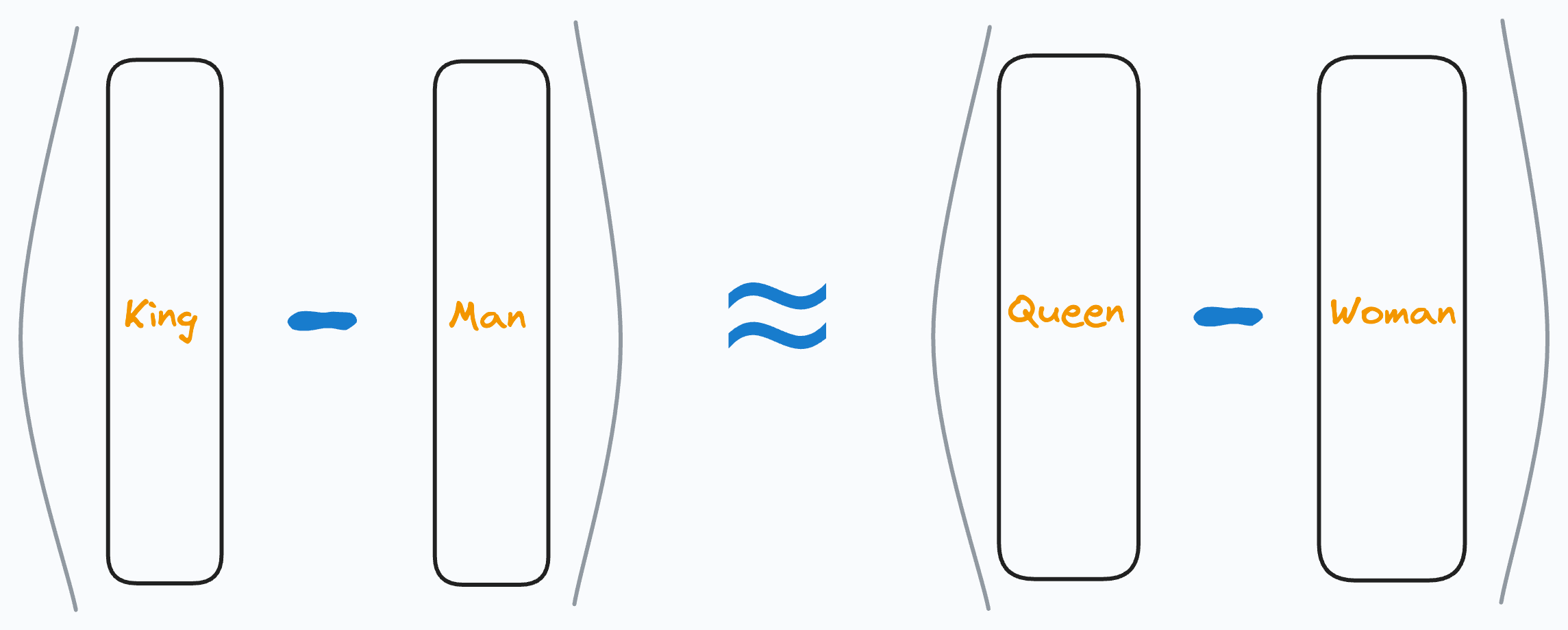
So while these did capture relative representations of words, there was a major limitation.
Consider the following two sentences:
“Convert this data into a table in Excel.”
“Put this bottle on the table.”
The word “table” conveys two entirely different meanings in the two sentences.
The first sentence refers to a “data” specific sense of the word “table”.
The second sentence refers to a “furniture” specific sense of the word “table”.
Yet, static embedding models assigned them the same representation.

Thus, these embeddings didn’t consider that a word may have different usages in different contexts.
But this changed in the Transformer era, which resulted in contextualized embeddings models powered by Transformers, such as:
BERT: A language model trained using two techniques:

BERT pre-training Masked Language Modeling (MLM): Predict a missing word in the sentence, given the surrounding words.
Next Sentence Prediction (NSP).
DistilBERT: A simple, effective, and lighter version of BERT which is around 40% smaller:

Training DistilBERT Utilizes a common machine learning strategy called student-teacher theory.
Here, the student is the distilled version of BERT, and the teacher is the original BERT model.
The student model is supposed to replicate the teacher model’s behavior.
ALBERT: A Lite BERT (ALBERT). Uses a couple of optimization strategies to reduce the size of BERT:
Eliminates one-hot embeddings at the initial layer by projecting the words into a low-dimensional space.
Shares the weights across all the network segments of the Transformer model.


These were capable of generating context-aware representations, thanks to their self-attention mechanism.
This would allow embedding models to dynamically generate embeddings for a word based on the context they were used in.
As a result, if a word would appear in a different context, the model would get a different representation.
This is precisely depicted in the image below for different uses of the word “Bank”.
For visualization purposes, the embeddings have been projected into 2d space using t-SNE.
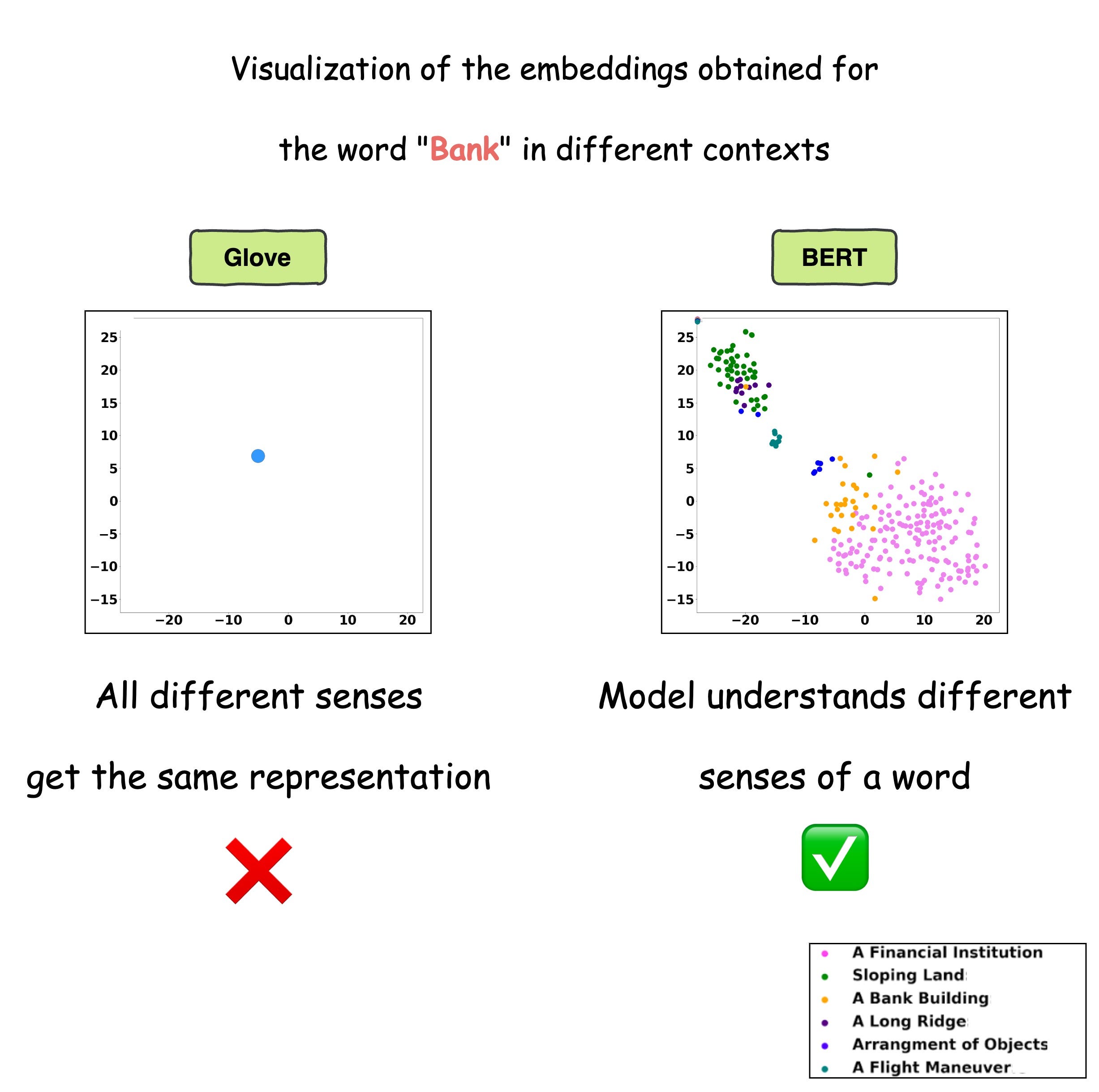
The static embedding models — Glove and Word2Vec produce the same embedding for different usages of a word.
However, contextualized embedding models don’t.
In fact, contextualized embeddings understand the different meanings/senses of the word “Bank”:
A financial institution
Sloping land
A Long Ridge, and more.
Different senses were taken from Priceton’s Wordnet database here: WordNet.
As a result, they addressed the major limitations of static embedding models.
For those who wish to learn in more detail, I published a couple of research papers on this intriguing topic:
Interpretable Word Sense Disambiguation with Contextualized Embeddings.
A Comparative Study of Transformers on Word Sense Disambiguation.
These papers discuss the strengths and limitations of many contextualized embedding models in detail.
👉 Over to you: What do you think were some other pivotal moments in NLP research?
While this is not something I typically tend to cover in my newsletters, I think amidst the GPT hype, the foundational stuff often gets overlooked.
And this gets increasingly intimidating for folks trying to get into this field.
So today’s newsletter was an attempt to help you look back into the early days, understand the pain points that existed back then, how they were addressed, and share some learnings from my research in this domain.
Hope you enjoyed :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Sponsor the Daily Dose of Data Science Newsletter. More info here: Sponsorship details.
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
An extremely comprehensible discussion of an extremely complex topic.
This topic is very relevant and crucial, thanks for shedding light on it. Quick question, while Glove and Word2Vec models would directly output a static word embedding vector, BERT and other Transformers based models would output a sequence of tokens; they compute the contextualized word embeddings implicitly. So, *what* vector is exactly being used from these Transformers based models as a contextualized embedding (is it one of the Q, K, V vectors)?