
The Most Underrated Way to Prune a Decision Tree in Seconds
Prune a decision tree in seconds with a Sankey diagram.

One thing I always appreciate about decision trees is their ease of visual interpretability.
No matter how many features our dataset has, we can ALWAYS visualize and interpret a decision tree.

In fact, this is not possible with other intuitive and simple models like linear regression. But decision trees stand out in this respect.
Nonetheless, one thing I often find a bit time-consuming and somewhat “hit-and-trially” is pruning a decision tree.
See, the problem is that under default conditions, decision trees ALWAYS 100% overfit the dataset, as depicted below:

Thus, pruning is ALWAYS necessary to reduce model variance.
While there are many ways to prune them visually, such as the one shown below:
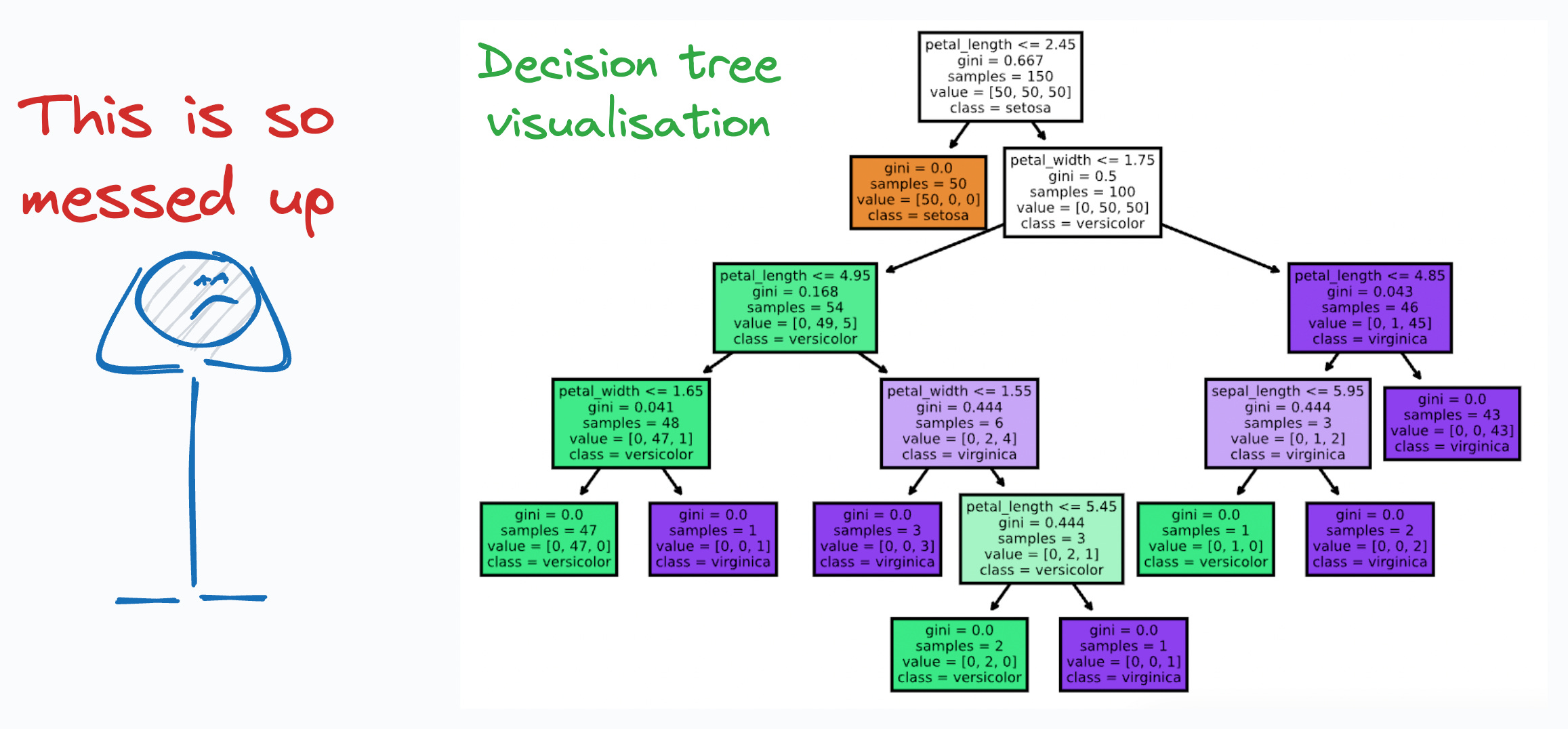
But the above visualisation is:
Pretty non-elegant, tedious, and messy.
Static (or non-interactive).
Instead, I have realized that an interactive Sankey diagram can be a great way to prune decision trees.
This is depicted below:
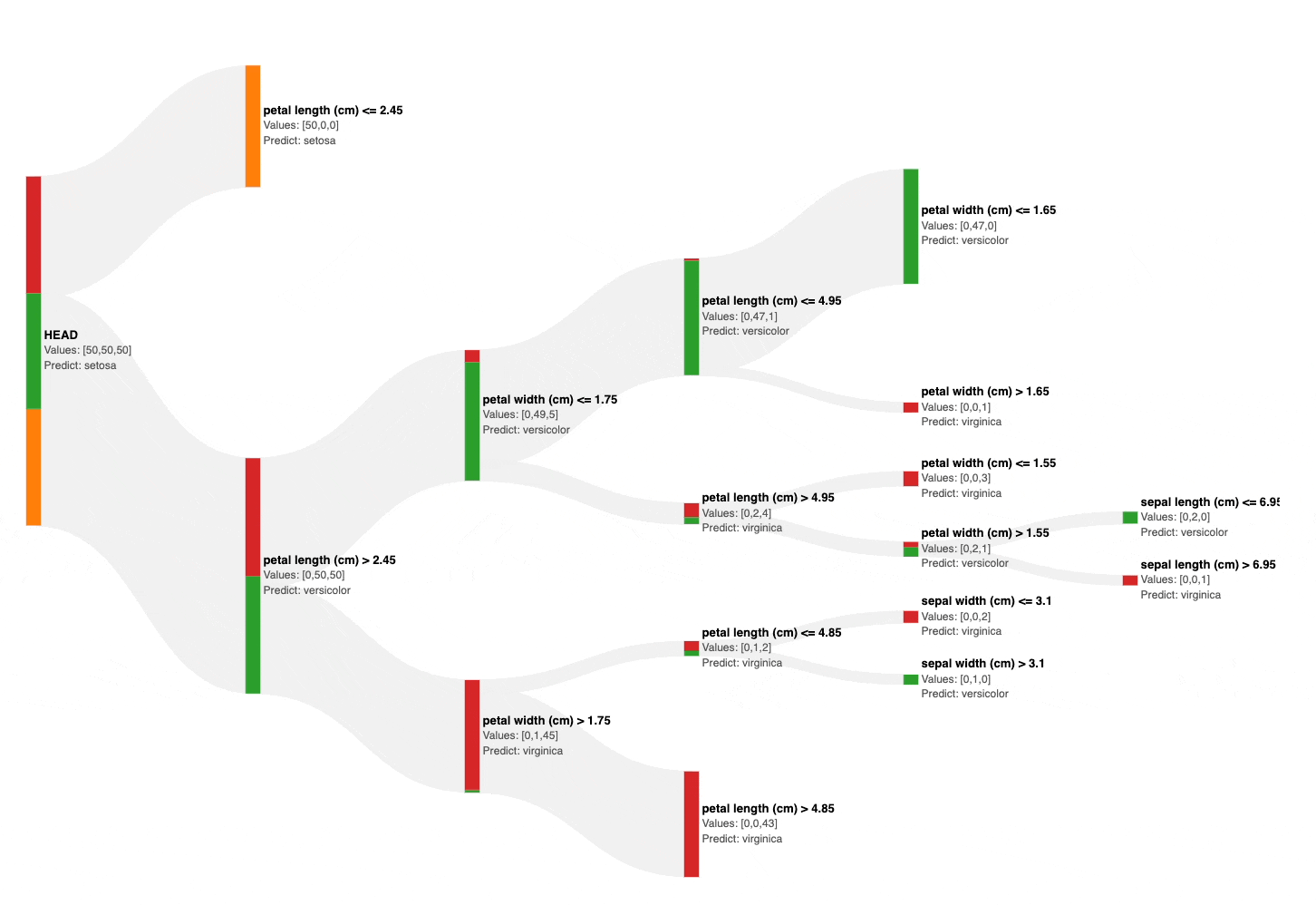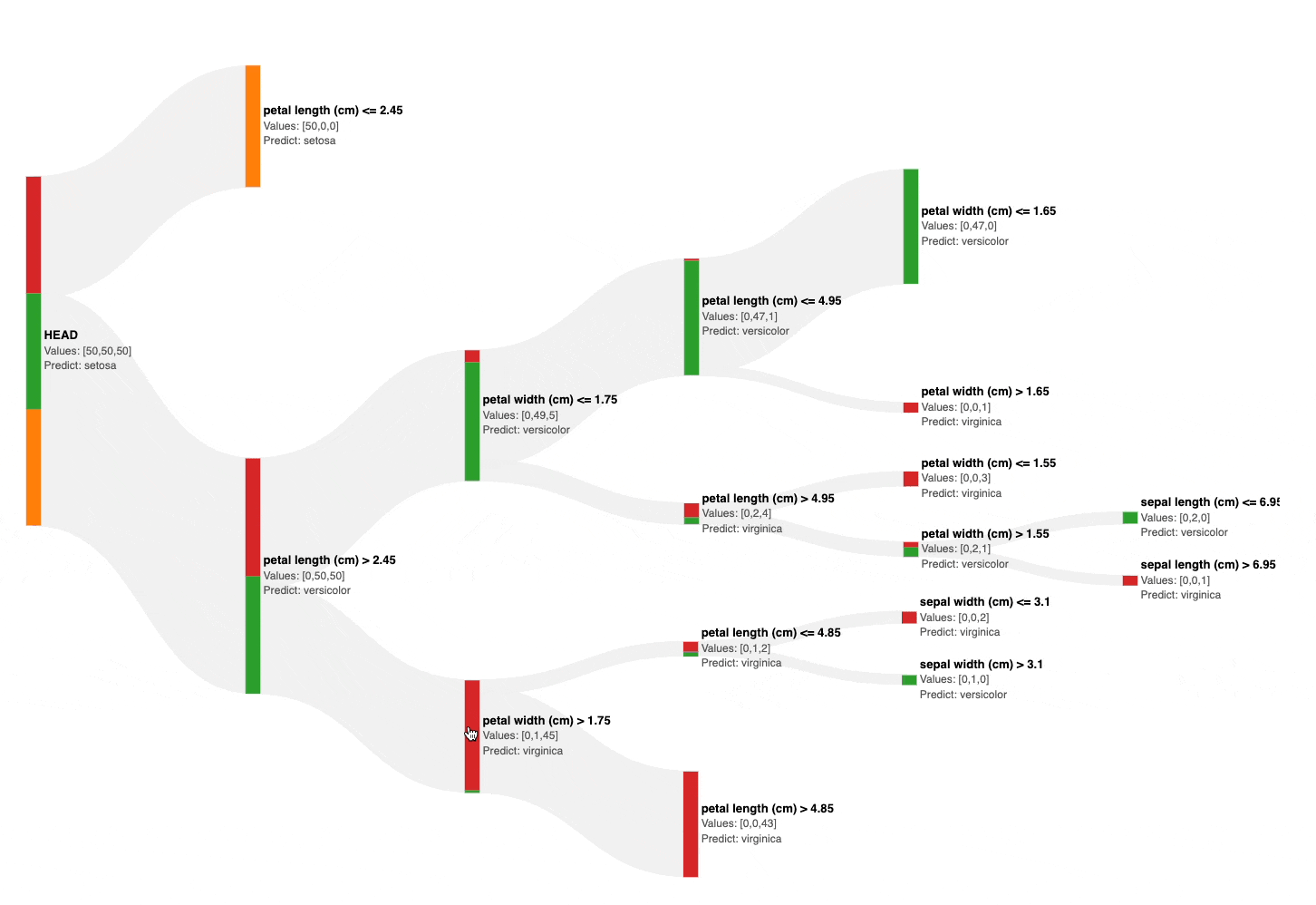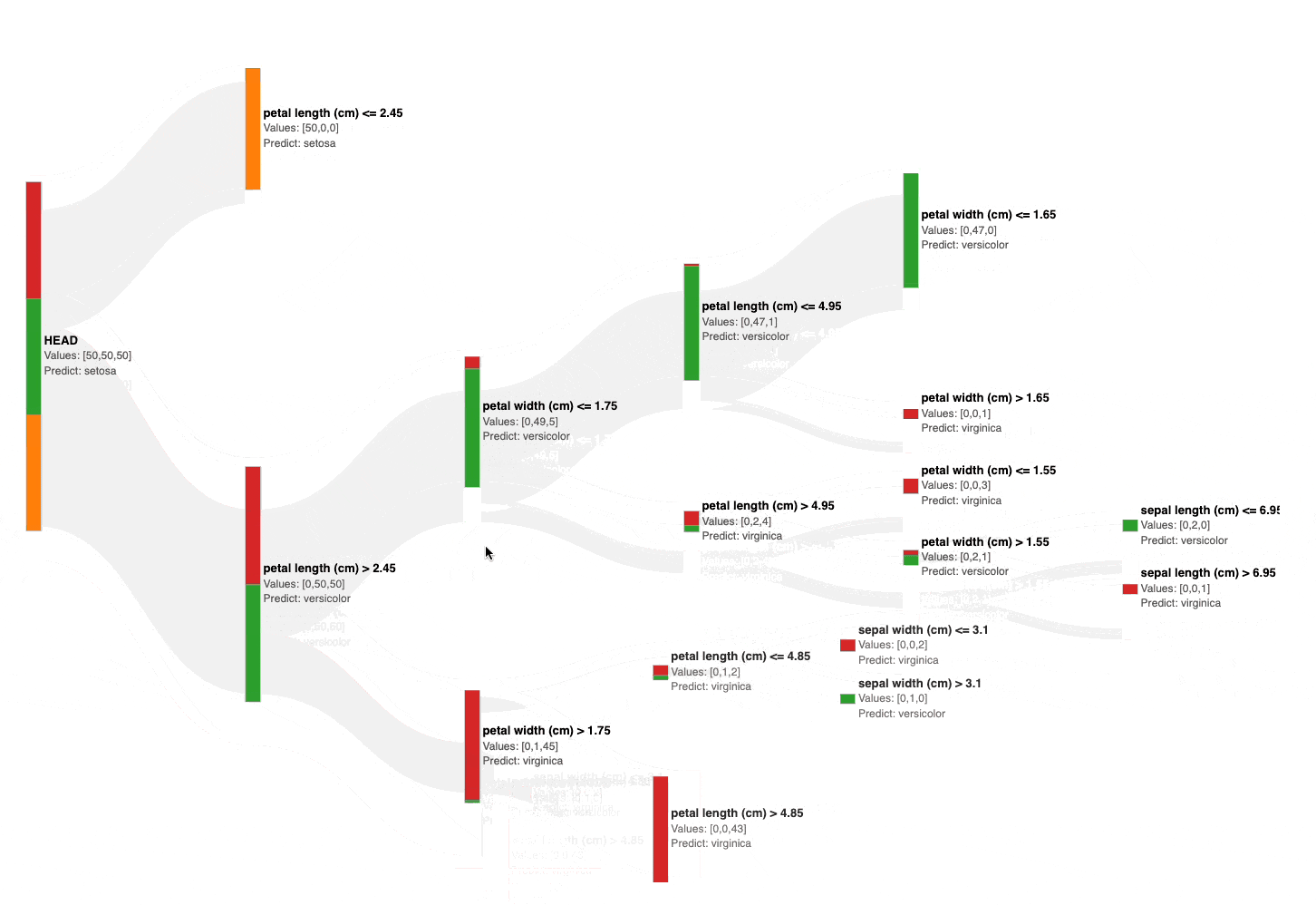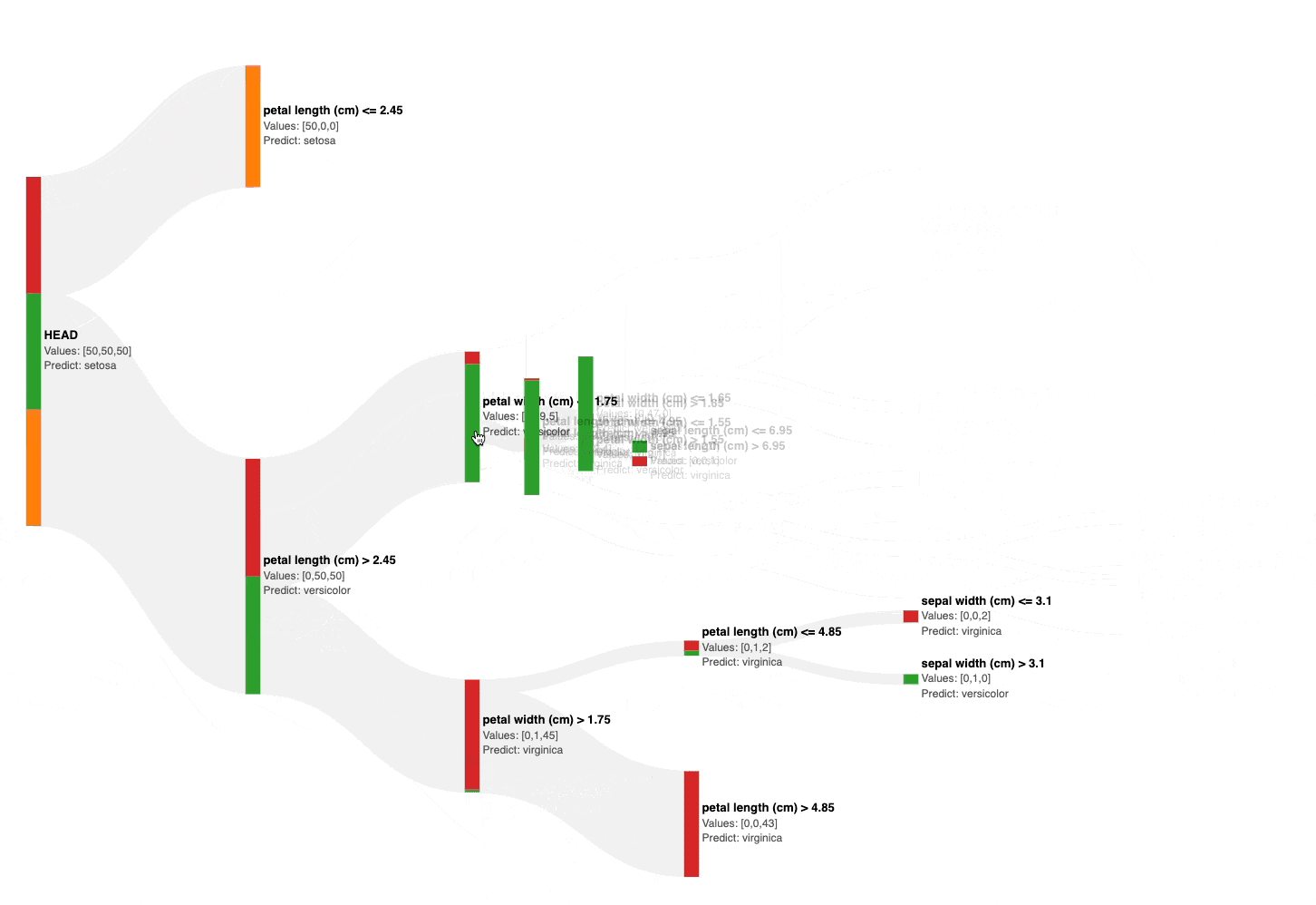
As shown above, the Sankey diagram allows us to interactively visualize and prune a decision tree by collapsing its nodes.
Also, the number of data points from each class is size and color-encoded in each node, as shown below.

This instantly gives an estimate of the node’s impurity, based on which, we can visually and interactively prune the tree in seconds.
For instance, in the full decision tree shown below, pruning the tree at a depth of two appears reasonable:
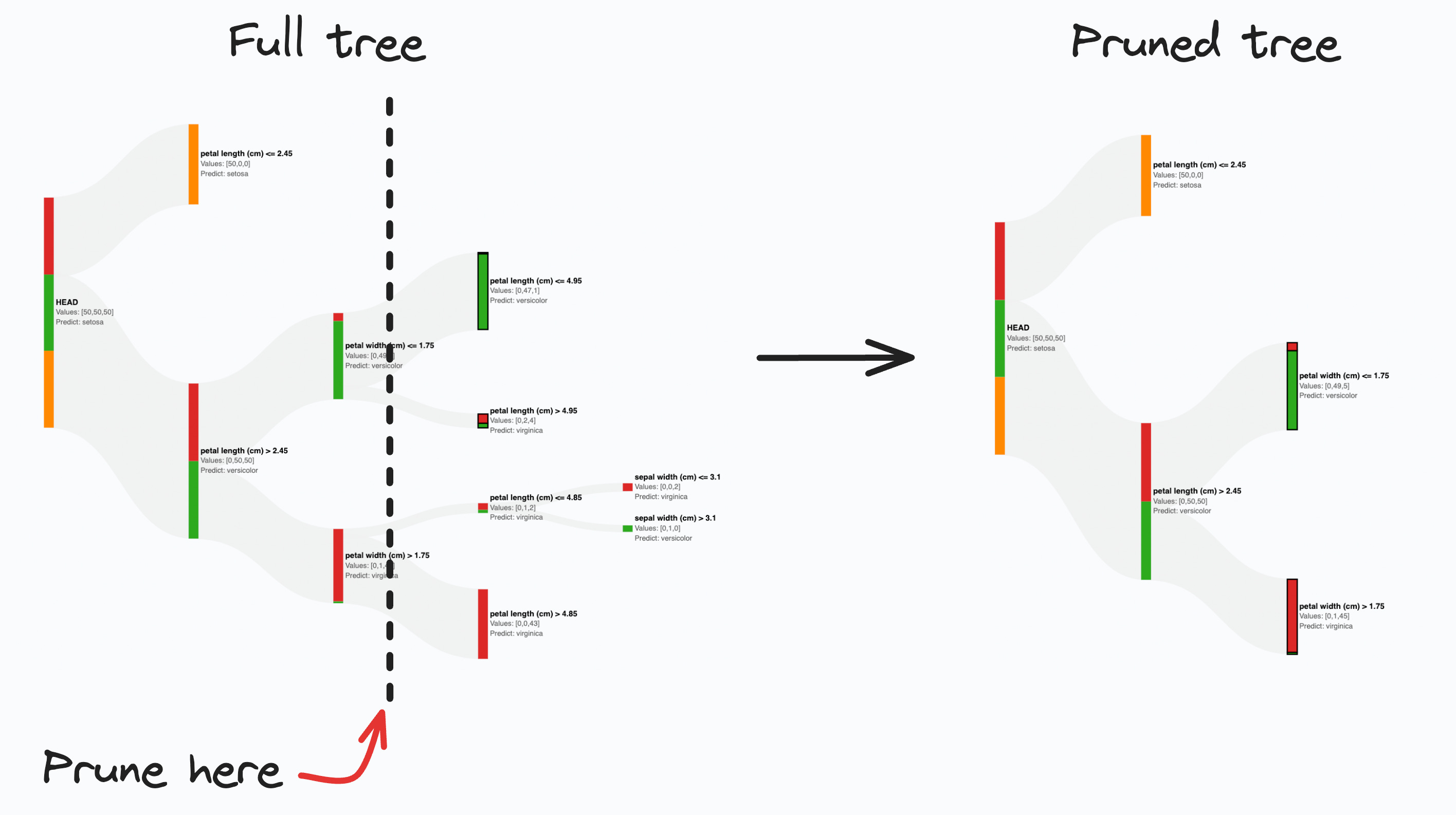
Next, we can train a new decision tree after obtaining an estimate for hyperparameter values.
This will help us reduce the variance of the decision tree.
Isn’t that cool?
That being said, another reliable remedy for reducing the variance of a decision tree model is using a random forest model:

The entire credit for variance reduction goes to Bagging.
You can find the full article to understand the entire mathematical foundation of Bagging: Why Bagging is So Ridiculously Effective At Variance Reduction?
It will help you truly understand why the random forest model is designed the way it is.

Also, you can download the code notebook for the interactive decision tree here: Interactive decision tree.
👉 Over to you: What are some other cool ways to prune a decision tree?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Model Compression: A Critical Step Towards Efficient Machine Learning.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
Formulating and Implementing the t-SNE Algorithm From Scratch.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Great article! Thanks for posting. I have 2 questions regarding the referenced Jupytr notebook, Plot_Interactive_Decision_Tree.jpynb:
1. Is the code in the notebook (and related html files), specific to the iris dataset? Or can it be used with other datasets without moddification?
2. Is the code specific to decision trees created using DecisionTreeClassifier()? Or will it work with other decision tree algorithms?
Thanks.