
The Ultimate Categorization of Clustering Algorithms
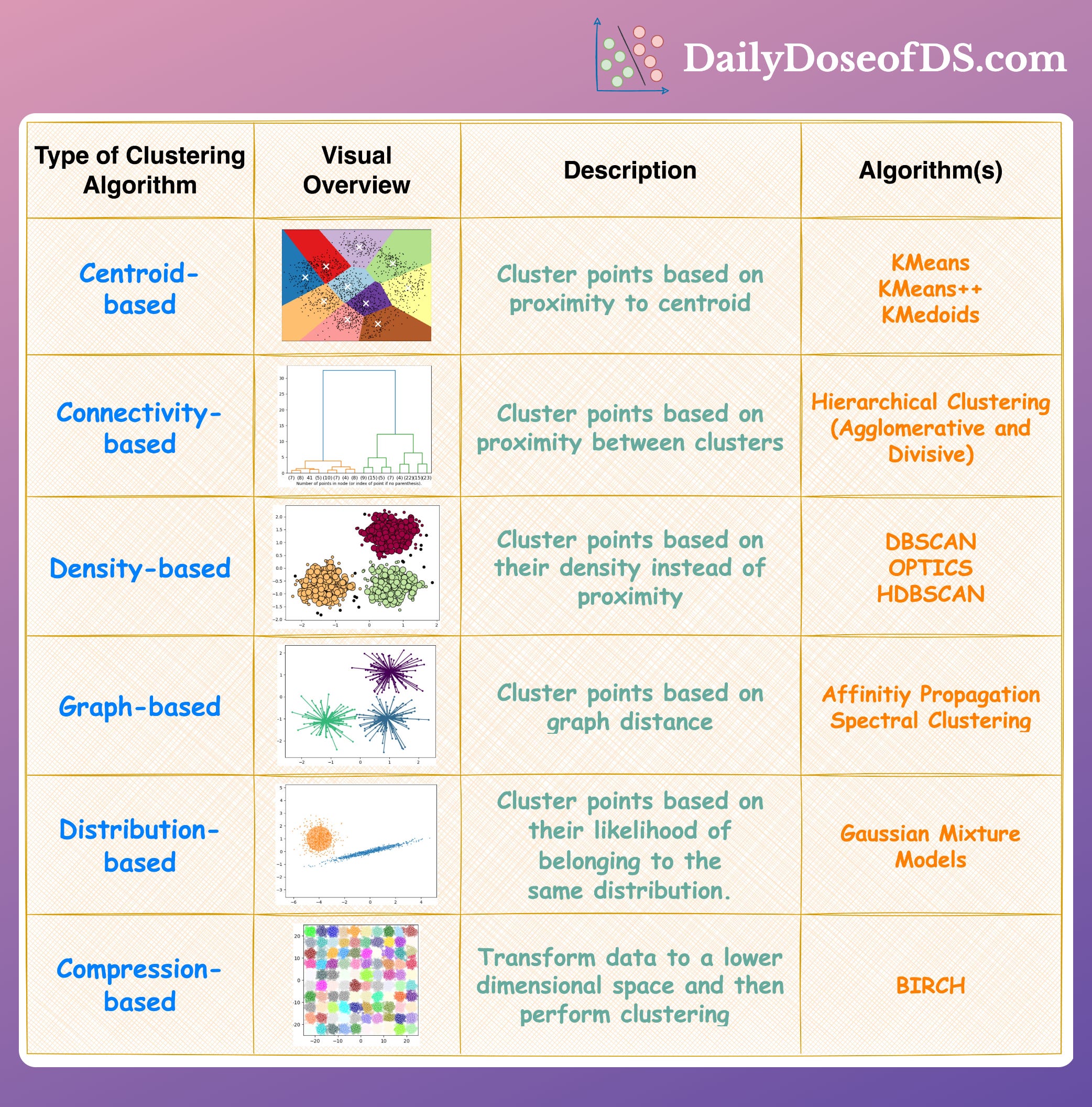
6 types of clustering algorithms in a single frame.

Clustering is one of the core branches of unsupervised learning in ML.
It involves grouping data points together based on their inherent patterns or characteristics.
By identifying similarities (and dissimilarities) within a dataset, clustering helps in revealing underlying structures, discovering hidden patterns, and gaining insights into the data.
While centroid-based is the most common class of clustering, there's a whole world of algorithms beyond that, which we all should be aware of.
Centroid-based: Cluster data points based on proximity to centroids.
Connectivity-based: Cluster points based on proximity between clusters.
Density-based: Cluster points based on their density.
Graph-based: Cluster points based on graph distance.
Distribution-based: Cluster points based on their likelihood of belonging to the same distribution.
Compression-based: Transform data to a lower dimensional space and then perform clustering
Over to you: What other clustering algorithms will you include here?
This post was inspired by the clustering document of Sklearn. If you wish to learn more details, I would highly recommend reading this: Sklearn Clustering Guide.
👉 Read what others are saying about this post on LinkedIn and Twitter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
Great summary, thanks!