
This Small Tweak Can Significantly Boost The Run-time of KMeans
KMeans++: KMeans with a smarter centroid initialization approach.

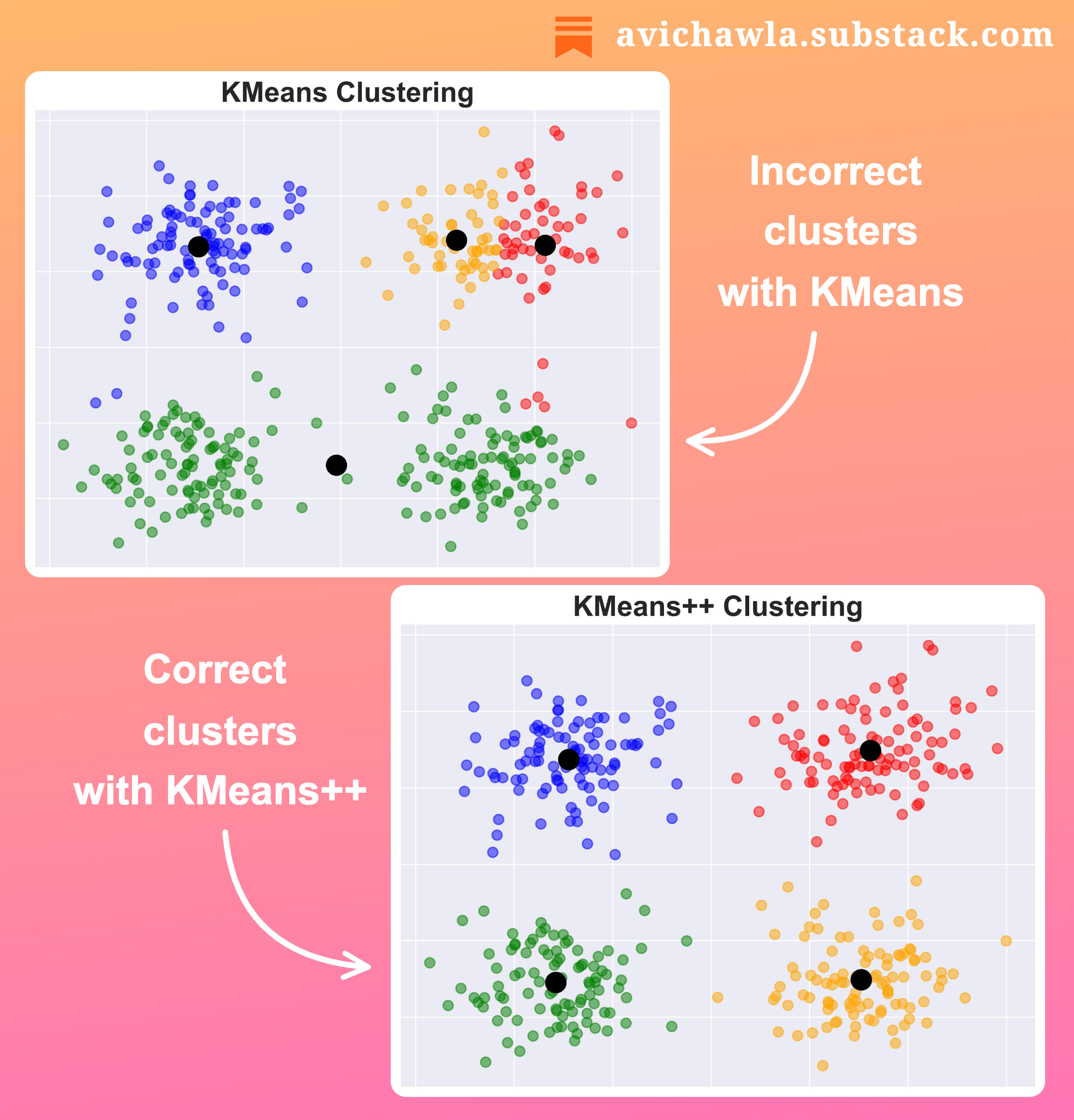
KMeans is a popular but high-run-time clustering algorithm. Here's how a small tweak can significantly improve its run time.
KMeans selects the initial centroids randomly. As a result, it fails to converge at times. This requires us to repeat clustering several times with different initialization.
Instead, KMeans++ takes a smarter approach to initialize centroids. The first centroid is selected randomly. But the next centroid is chosen based on the distance from the first centroid.
In other words, a point that is away from the first centroid is more likely to be selected as an initial centroid. This way, all the initial centroids are likely to lie in different clusters already and the algorithm may converge faster.
The illustration below shows the centroid initialization of KMeans++:

👉 See what others are saying about this post on LinkedIn: Post Link.
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn.