
Why is Iteration Ridiculously Slow in Pandas DataFrames?
No, vectorization is not the answer!

When using Pandas, we are always advised to avoid iterating on a DataFrame. If we do, it results in a high run-time.
This is evident from the image below:

Accessing a column with over 32 million elements is still over 20x faster than accessing a row with just 9 elements.
I am sure you must have heard about this plenty of times so I will not give you the same advice again.
Instead, I want you to question this useful yet often unexplained advice.
More specifically, what is the reason behind this? Why are we advised to avoid iterating a DataFrame?
Many say vectorization, but that’s not an entirely correct answer here.
See, vectorization results from optimizations that are applied:
when dealing with a batch of data together…
…and by avoiding native Python for-loops (which are slow).
If a column is a batch of data, so is a row, right?

So isn’t it worth questioning that if we can apply vectorization to a DataFrame’s column, why can’t we do it with its rows as well?
Let’s understand the core reason behind this.
To better understand the cause of this problem, we must understand the Pandas DataFrame data structure and how it is stored in memory.
A DataFrame is a column-major data structure.
This means that consecutive elements in a column are stored next to each other in memory, as depicted below:
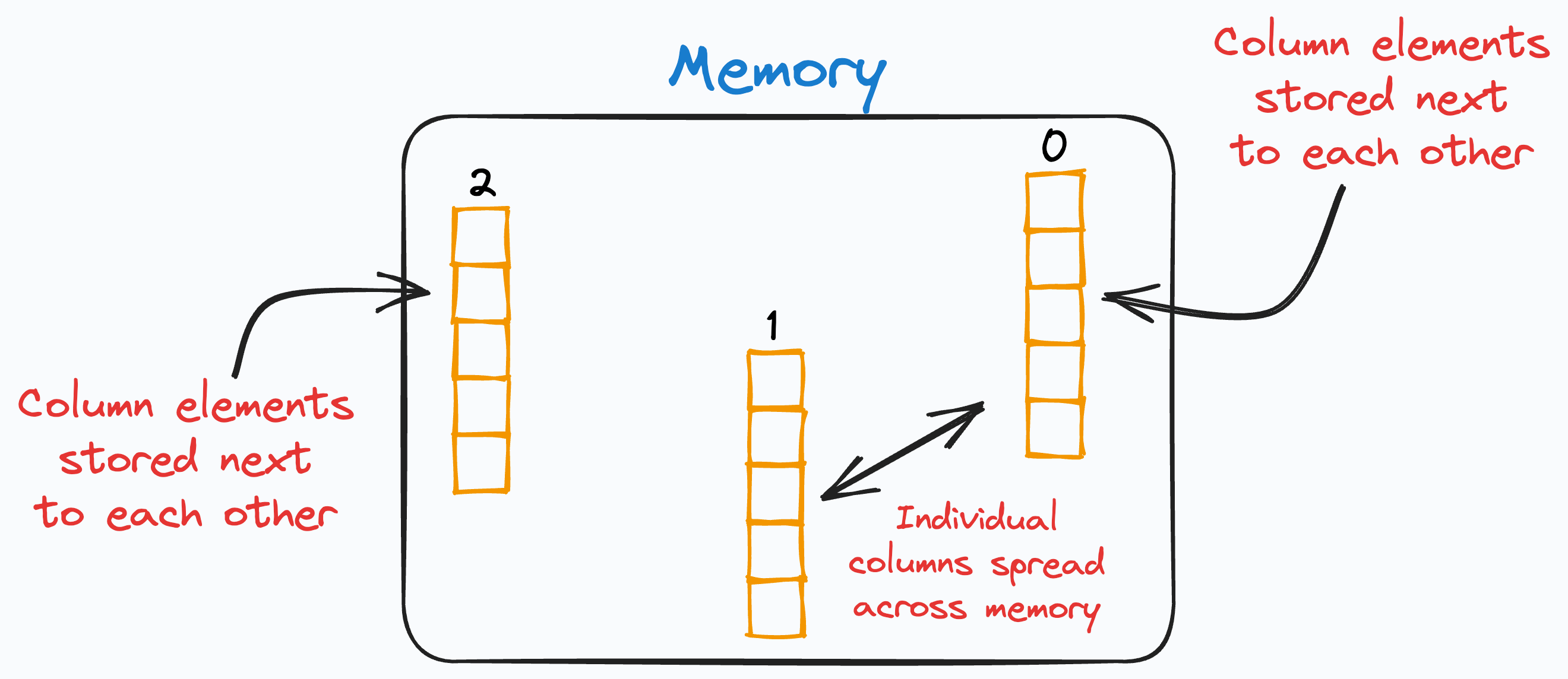
Of course, the individual columns may be spread across different locations in memory. However, the elements of each column are ALWAYS together.
As processors are much more efficient with contiguous blocks of memory, retrieving a column is much faster than fetching a row.

In other words, when iterating, each row is retrieved by accessing non-contiguous blocks of memory.
The processor must continually move from one memory location to another to grab all row elements.
As a result, the run-time increases drastically.
That is why we are always advised to avoid iterating over a DataFrame.
👉 Over to you: What are some things we should be careful of when using a Pandas DataFrame?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Found today’s newsletter valuable?
If yes, then check out the full (20-30 mins) deep dives that help you cultivate practical data science and machine learning skills.
Here’s what we covered last month:
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Model Compression: A Critical Step Towards Efficient Machine Learning.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Thanks, didn't know that. A few practical examples wouldn't be redundant...