
Why Sklearn's Linear Regression Implementation Has No Hyperparameters?
What are we missing here?

Almost all ML models we work with have some hyperparameters, such as:
Learning rate
Regularization
Layer size (for neural network), etc.
But as shown in the image below, why don’t we see any hyperparameter in Sklearn’s Linear Regression implementation?

It must have learning rate as a hyperparameter, right?
To understand the reason why it has no hyperparameters, we first need to learn that the Linear Regression can model data in two different ways:
Gradient Descent (which many other ML algorithms use for optimization):
It is a stochastic algorithm, i.e., involves some randomness.
It finds an approximate solution using optimization.
It has hyperparameters.
Ordinary Least Square (OLS):
It is a deterministic algorithm. Thus, if run multiple times, it will always converge to the same weights.
It always finds the optimal solution.
It has no hyperparameters.
Now, instead of the typical gradient descent approach, Sklearn’s Linear Regression class implements the OLS method.
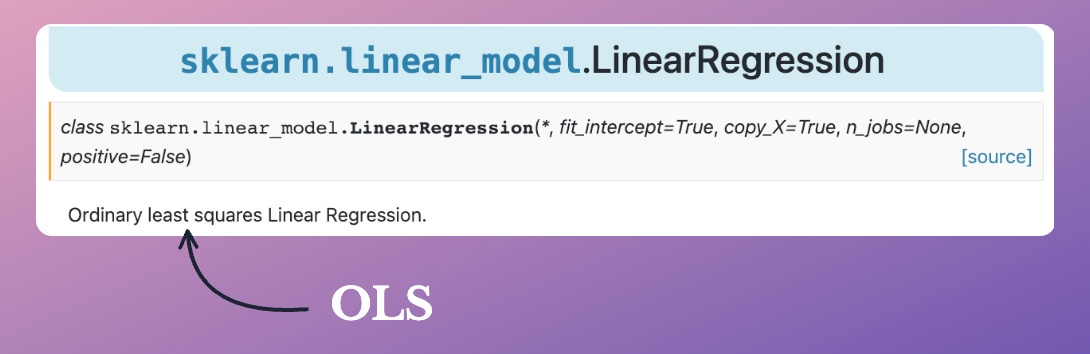
That is why it has no hyperparameters.
How does OLS work?
With OLS, the idea is to find the set of parameters (Θ) such that:
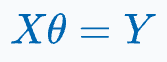
where,
X: input data with dimensions(n,m).Θ: parameters with dimensions(m,1).y: output data with dimensions(n,1).n: number of samples.m: number of features.
One way to determine the parameter matrix Θ is by multiplying both sides of the equation with the inverse of X, as shown below:

But because X might be a non-square matrix, its inverse may not be defined.
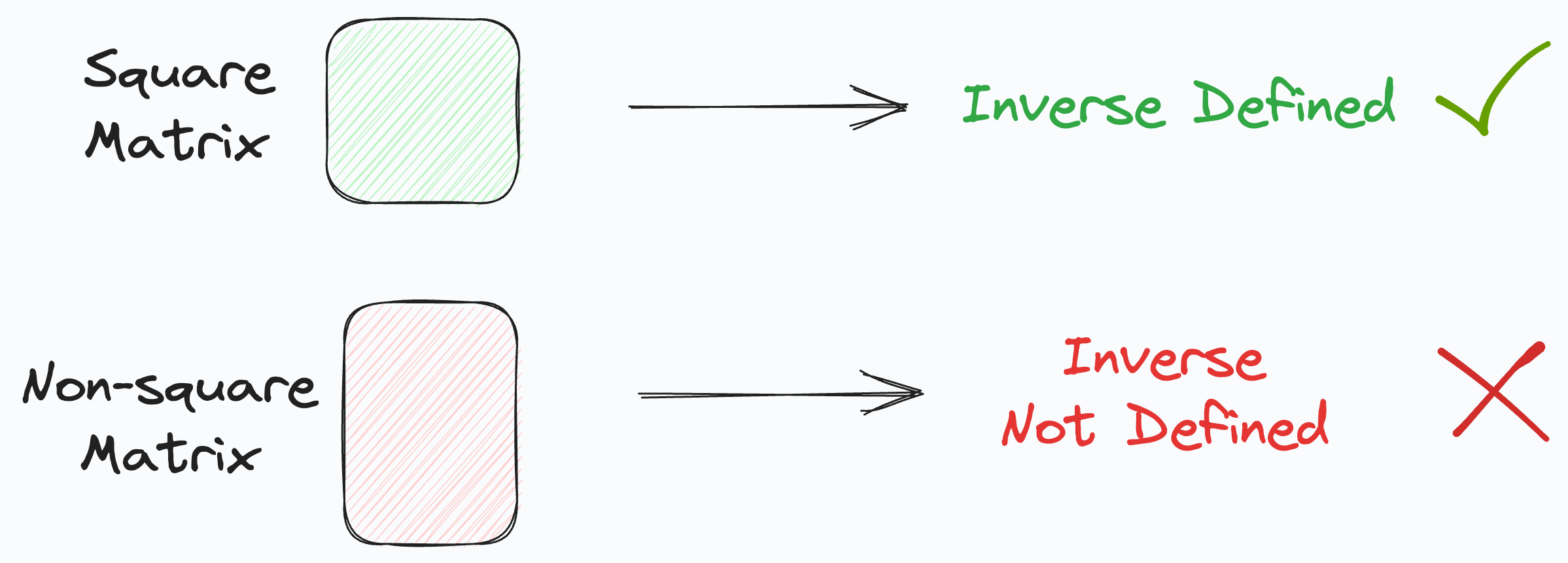
To resolve this, first, we multiply with the transpose of X on both sides, as shown below:
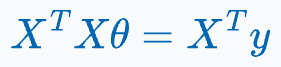
This makes the product of X with its transpose a square matrix.

The obtained matrix, being square, can be inverted (provided it is non-singular).
Next, we take the collective inverse of the product to get the following:

It’s clear that the above equation has:
No hyperparameters.
No randomness. Thus, it will always return the same solution, which is also optimal.
This is precisely what the Linear Regression class of Sklearn implements.
To summarize, it uses the OLS method instead of gradient descent.
That is why it has no hyperparameters.
Of course, do note that there is a significant tradeoff between run time and convenience when using OLS vs. gradient descent.
This is also clear from the algorithm time-complexity table I once shared in this newsletter:

As depicted above, the run-time of OLS is cubically related to the number of features (m).
Thus, when we have many features, it may not be a good idea to use the LinearRegression() class. Instead, use the SGDRegressor() class from Sklearn.
That said, the good thing about LinearRegression() class is that it involves no hyperparameter tuning.
Thus, when we use OLS, we trade run-time for finding an optimal solution without hyperparameter tuning.
👉 Over to you: How would you prove that the solution returned by OLS is optimal? Would love to read your answers :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed:
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Thank you. I am sending this on to my kid, a sophomore in a UC who is not sure that stats would be a useful course. The way you took it back to basics and brought it into present use was delicious. Keep writing, please.