Daily Dose of Data Science
Subscribe
Sign in
Home
Premium
Archive
About
Machine Learning
Latest
Top
Discussions
25 Most Important Mathematical Definitions in Data Science
...in a single frame.
Apr 25
•
Avi Chawla
35
Share this post
25 Most Important Mathematical Definitions in Data Science
blog.dailydoseofds.com
Copy link
Facebook
Email
Note
Other
8 Fatal (Yet Non-obvious) Pitfalls in Data Science
...and how to identify and handle them.
Apr 23
•
Avi Chawla
30
Share this post
8 Fatal (Yet Non-obvious) Pitfalls in Data Science
blog.dailydoseofds.com
Copy link
Facebook
Email
Note
Other
2
Intrinsic Measures for Clustering Evaluation
Three reliable methods for clustering evaluation.
Apr 22
•
Avi Chawla
27
Share this post
Intrinsic Measures for Clustering Evaluation
blog.dailydoseofds.com
Copy link
Facebook
Email
Note
Other
11 Key Probability Distributions in Data Science
Essential for statistical modeling.
Apr 20
•
Avi Chawla
43
Share this post
11 Key Probability Distributions in Data Science
blog.dailydoseofds.com
Copy link
Facebook
Email
Note
Other
Train Classical ML Models on Large Datasets
Extending the Bagging objective.
Apr 18
•
Avi Chawla
21
Share this post
Train Classical ML Models on Large Datasets
blog.dailydoseofds.com
Copy link
Facebook
Email
Note
Other
3
How To Avoid Getting Misled by t-SNE Projections?
Some key and lesser-known observations from t-SNE results.
Apr 17
•
Avi Chawla
17
Share this post
How To Avoid Getting Misled by t-SNE Projections?
blog.dailydoseofds.com
Copy link
Facebook
Email
Note
Other
5 Must-Know Ways to Test ML Models in Production
...with implementation.
Apr 14
•
Avi Chawla
19
Share this post
5 Must-Know Ways to Test ML Models in Production
blog.dailydoseofds.com
Copy link
Facebook
Email
Note
Other
Train and Test-time Data Augmentation
More data from existing data.
Apr 12
•
Avi Chawla
and
Banias Baabe
18
Share this post
Train and Test-time Data Augmentation
blog.dailydoseofds.com
Copy link
Facebook
Email
Note
Other
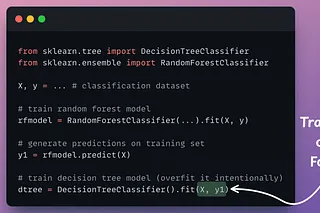
Condense Random Forest into a Decision Tree
Preserve generalization power while reducing run-time.
Apr 9
•
Avi Chawla
37
Share this post
Condense Random Forest into a Decision Tree
blog.dailydoseofds.com
Copy link
Facebook
Email
Note
Other
3
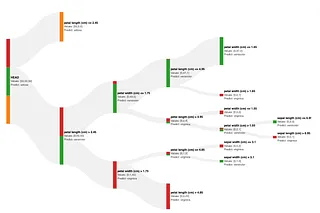
Interactively Prune a Decision Tree
Prune a decision tree in seconds with a Sankey diagram.
Apr 7
•
Avi Chawla
24
Share this post
Interactively Prune a Decision Tree
blog.dailydoseofds.com
Copy link
Facebook
Email
Note
Other
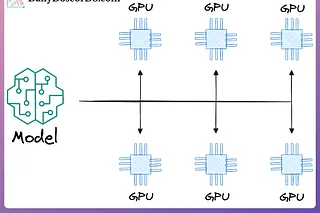
A Beginner-friendly Guide to Multi-GPU Training
Learn how to scale models using distributed training.
Apr 6
•
Avi Chawla
34
Share this post
A Beginner-friendly Guide to Multi-GPU Training
blog.dailydoseofds.com
Copy link
Facebook
Email
Note
Other
What is Bhattacharyya Distance?
...And how it differs from KL divergence.
Apr 5
•
Avi Chawla
25
Share this post
What is Bhattacharyya Distance?
blog.dailydoseofds.com
Copy link
Facebook
Email
Note
Other
3
Share
Copy link
Facebook
Email
Note
Other
This site requires JavaScript to run correctly. Please
turn on JavaScript
or unblock scripts